Hosting and Virtual Hosts
Tung Nguyen
11 min read
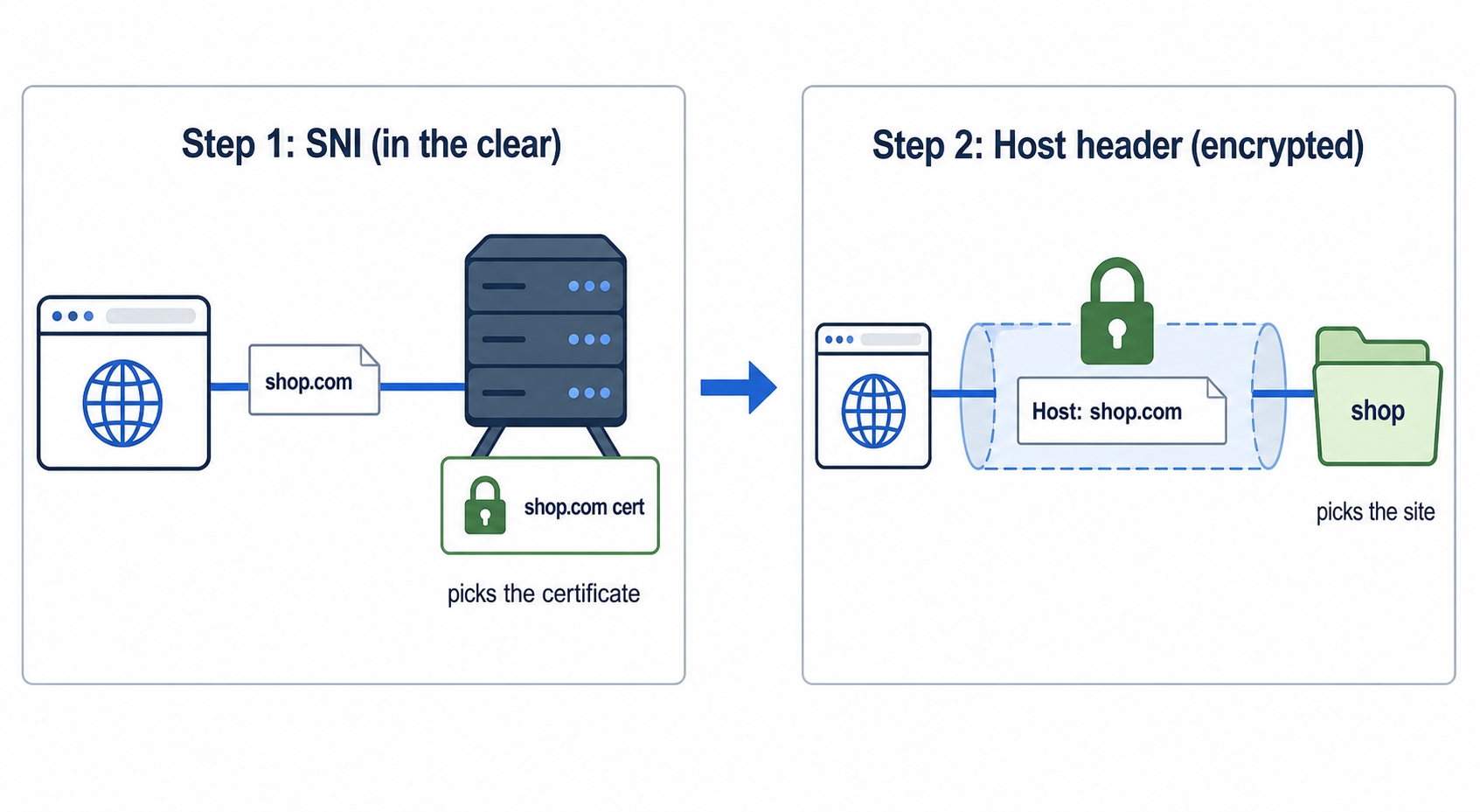
That closes out how HTTP carries and labels its payloads. Now we move into running HTTP in production, and the first question is a money question: a small website does not need a whole server to itself, so how does one machine host hundreds of different sites at once? We have already met both halves of the answer earlier in the course, the Host header and SNI. This chapter puts them together.
Here is the puzzle. You have one server with one public IP address. Pointed at that single address are shop.example.com, blog.example.com, and a hundred other domains, each a different website with different content. A request arrives. The server can see the IP it came in on, but that IP is the same for every site it hosts. So how does it know which site you actually wanted?
What virtual hosting means
Virtual hosting is running more than one website on a single server. The word "virtual" is the giveaway: from the outside each site looks like it has its own server, but they all share one machine, and often one IP address.
There were historically two ways to do this, and the difference is worth a sentence because it explains why the modern web looks the way it does.
The old way was IP-based virtual hosting: give the server several IP addresses, one per site, and tell the sites apart by which IP the request landed on. It works, but IPv4 addresses are scarce and expensive, so handing one to every small blog does not scale.
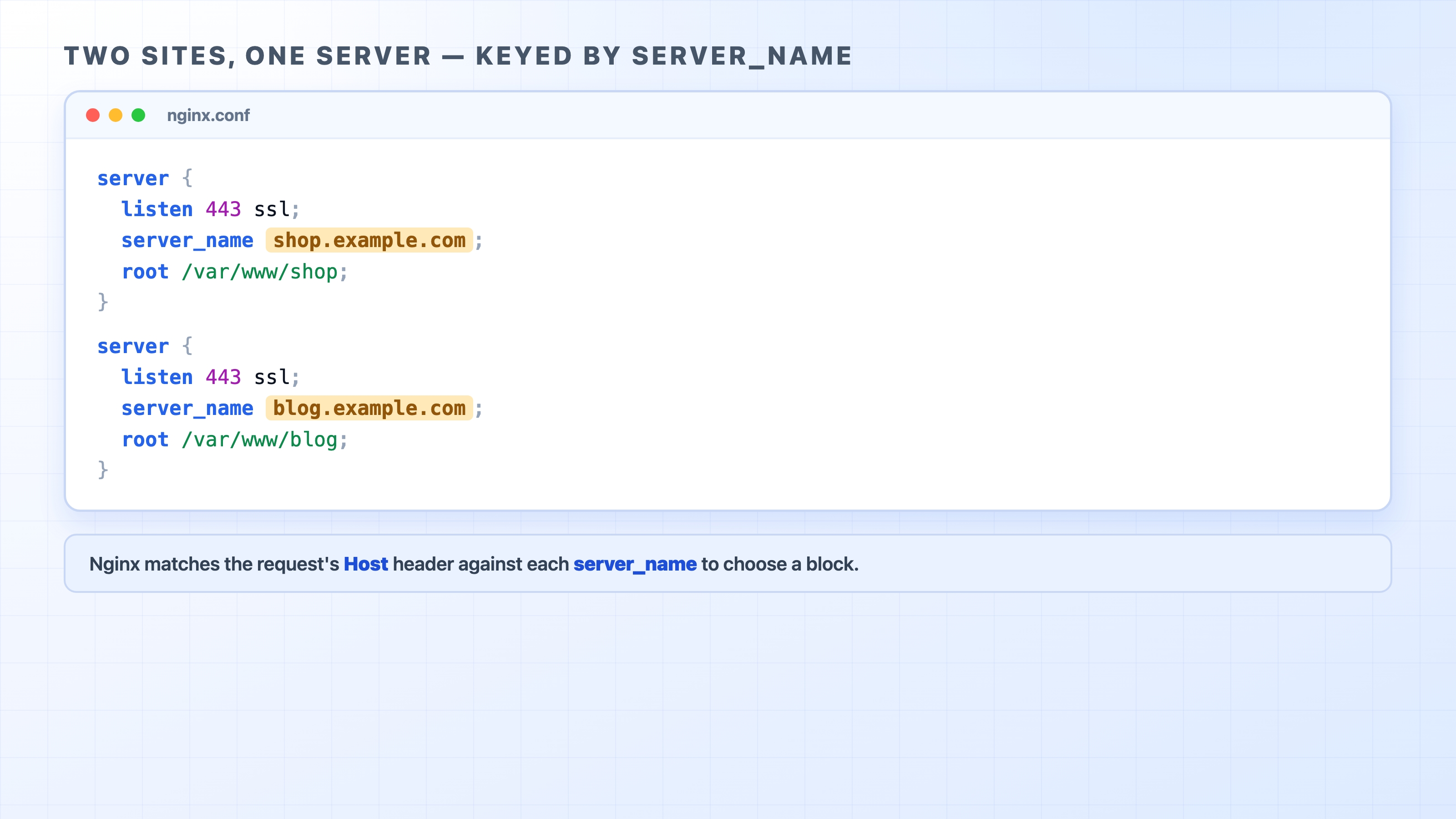
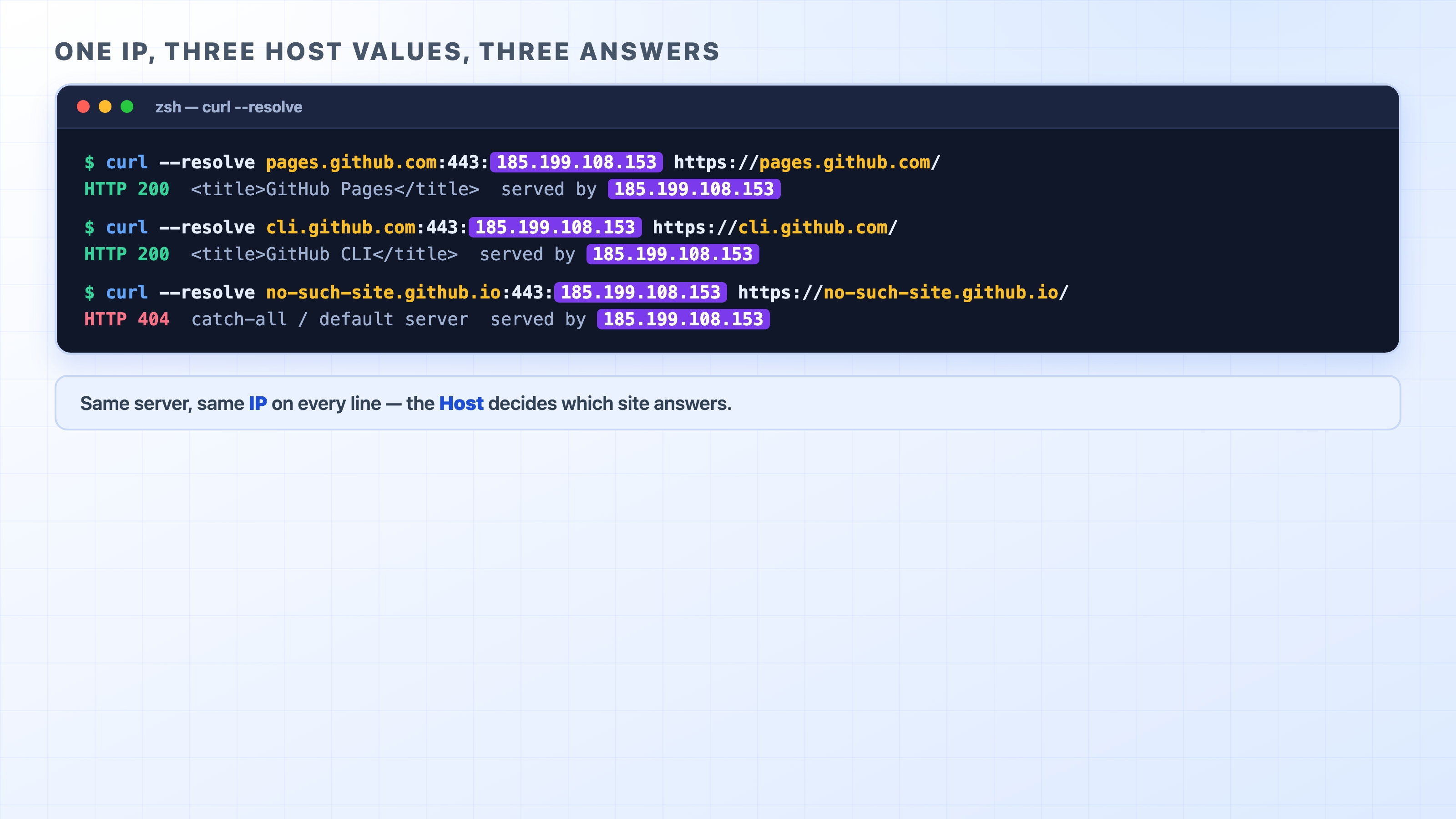
The way the whole web runs today is name-based virtual hosting: one IP, many sites, told apart not by the address but by the name the client asked for. That name travels in the request, and the server reads it to decide which site should answer.
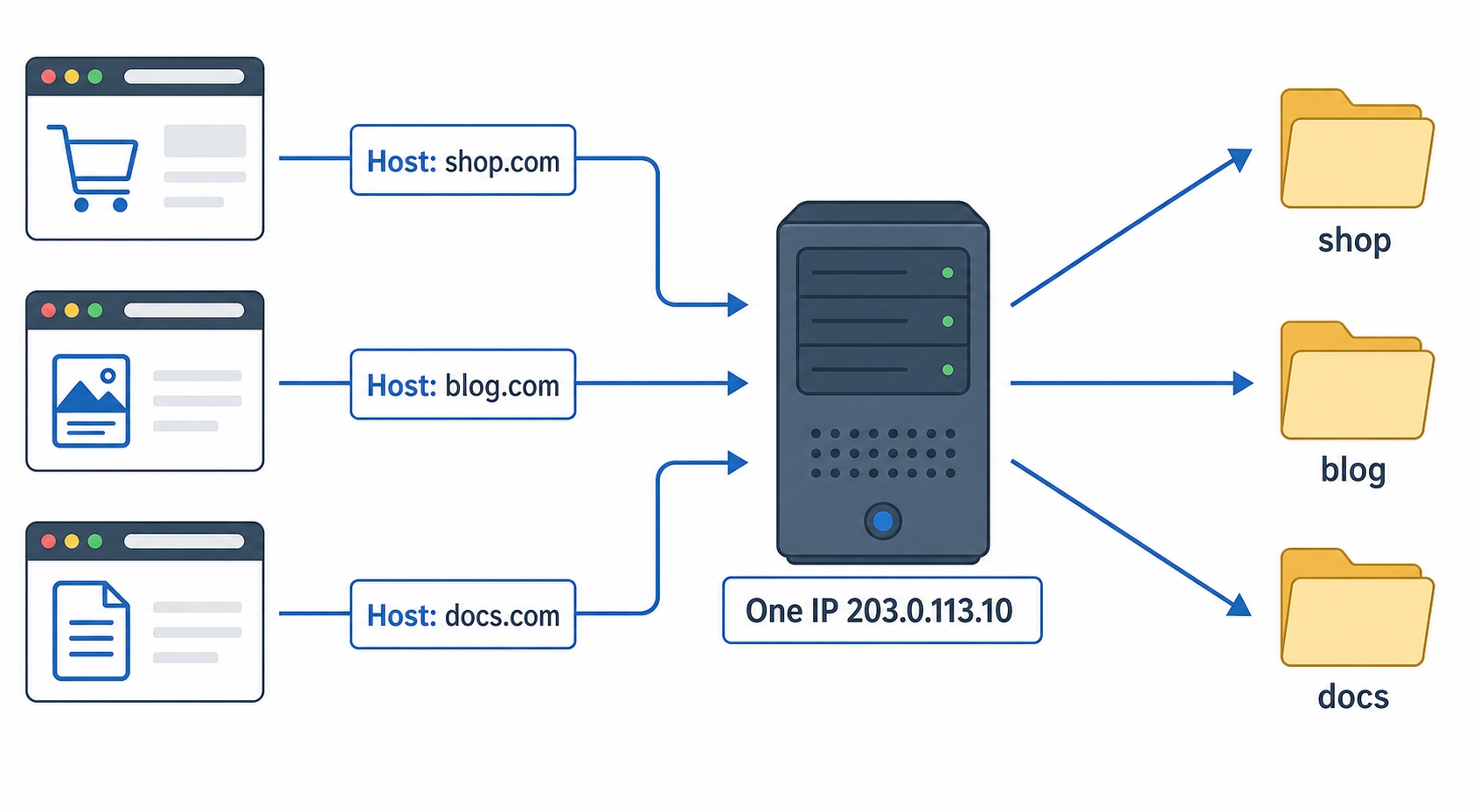
That picture is the entire idea. Three different requests reach one server at one IP. Each one carries a different site name. The server reads the name, finds the matching site, and serves it. Same machine, same address, three completely different websites.