That closes out virtual hosting: a request arrives, the server reads the Host header, and it picks the right site to answer. But picking the right site is only half the job. One of the most common things a production server does immediately after that is tell the browser the page is somewhere else. The bare-IP visitor gets bounced to a real domain. The http:// visitor gets pushed to https://. The www. visitor gets sent to the canonical name. Every one of those is a redirect, and they are so routine that the first response your browser gets from a typical site is often not the page at all.
What a redirect actually is
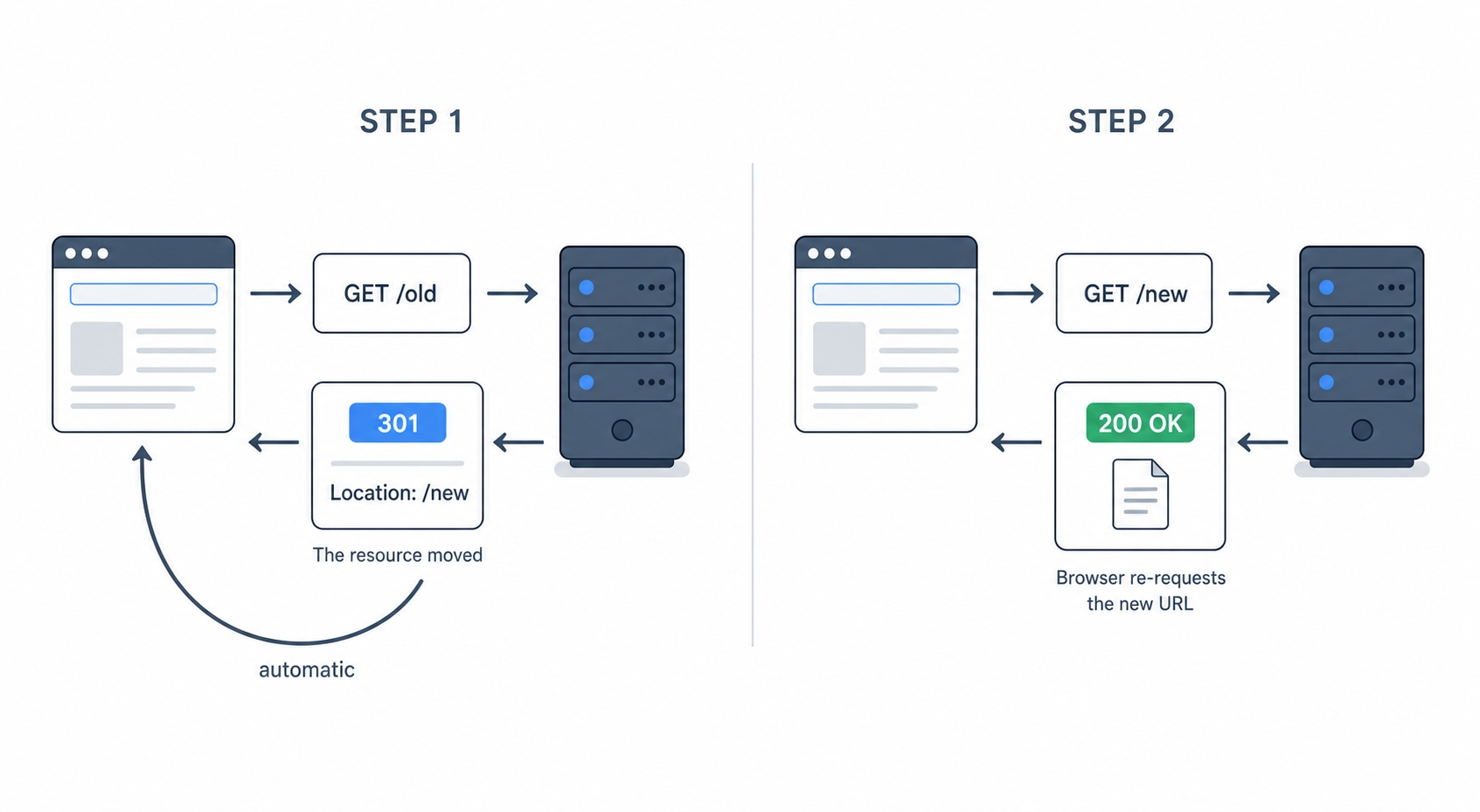
A redirect is a response that says "I'm not giving you the page, go ask for it at this other URL instead." The server does not return the content. It returns two things:
a status code in the 3xx range (the redirect family, from the status-codes chapter)
a Location header holding the URL the client should go to next
That is the whole mechanism. The client reads the 3xx code, sees the Location, and automatically sends a brand-new request to that URL. You typed one address; the browser quietly made two requests, and you only ever saw the final page.
A 301 plus a Location header sends the client to a new URL
Here is what that looks like as raw HTTP. The browser asks for the old address:
GET / HTTP/1.1
Host: github.com
http
The server does not send a page. It sends a redirect:
HTTP/1.1 301 Moved Permanently
Location: https://github.com/
http
There is no HTML body to render here. The status line says and the header names the new URL. The browser reads both, then fires off a second request to , and response is the actual page with a . The redirect is invisible to you because the browser follows it for you.
HTTP Redirects: 301 vs 302 vs 307 vs 308 | dalabs.academy
301
Location
https://github.com/
that
200 OK
A common point of confusion. The Location header only matters on a 3xx response. The same header name shows up on a 201 Created to point at the newly created resource, but that is not a redirect and the browser will not jump to it. A redirect is the combination of a 3xx status and Location together.
Try it now
You can watch this happen against a real site. github.com over plain HTTP redirects you to HTTPS, so it is a clean example. The -I flag tells curl to fetch only the headers (a HEAD-style request), which is exactly what we want, since the interesting part of a redirect is the headers, not a body:
curl -I http://github.com
bash
HTTP/1.1 301 Moved Permanently
Content-Length: 0
Location: https://github.com/
text
There it is, live: a 301 and a Location pointing at the https:// version. Notice Content-Length: 0, the server is explicitly telling you there is no body. By default curl stops here and shows you just the redirect. To make it actually follow the Location, add -L:
curl -IL http://www.github.com
bash
HTTP/1.1 301 Moved Permanently
Location: https://www.github.com/
HTTP/2 301
location: https://github.com/
HTTP/2 200
text
This one chains two redirects. Start at http://www.github.com and read the hops top to bottom:
https://www.github.com/ → 301 → Location: https://github.com/ (the www. name gets sent to the bare name)
https://github.com/ → 200 (the real page, at last)
curl follows http to https then www to non-www to a 200
One address you typed, three requests, two redirects, and a final 200. -L is the flag that turns "show me the redirect" into "walk the whole chain and show me where it ends up." Keep it in mind, because it is also how you debug a redirect that has gone wrong.
The four redirects you'll meet
So far every example has been a 301. But there are four redirect codes you actually need to know, and the difference between them is not academic, picking the wrong one is a real bug. They split along two questions: is the move permanent or temporary, and does the client keep the original method when it re-requests?
301 302 307 and 308 compared by permanence and method
Code
Meaning
Cached by default
Method preserved
301
Moved Permanently
Yes
No
302
Found (temporary)
No
No
307
Temporary Redirect
No
Yes
308
Permanent Redirect
Yes
Yes
Read the table as two pairs. The left axis is permanence: 301 and 308 mean "this move is forever, remember it"; 302 and 307 mean "just for now, don't get attached." The right axis is method preservation, and this is the part that trips people up.
The method-switching gotcha
When a client follows a 301 or a 302, it is allowed to change the request method. In practice, when the original request was a POST, browsers and many HTTP clients turn the follow-up request into a GET and drop the body. That behavior is so old and so widespread that it became expected, and it is usually fine for the common case (a form posts, then redirects you to a confirmation page you fetch with GET).
It is a disaster when you did not want the method to change. Imagine a POST /api/orders that the server answers with a 302 to a new endpoint. A client that switches to GET will re-request the new URL with no body and the wrong method, and your order quietly vanishes.
That is exactly what 307 and 308 fix. They are the strict versions: the client must repeat the original method and body. A POST that hits a 308 stays a POST all the way to the new URL.
The safe rule of thumb. For a permanent move, use 308; for a temporary one, use 307. Both preserve the method, so they behave the same no matter what request hit them. Reach for 301 and 302 only for the classic case of redirecting a GET to another GET, where the possible method switch does no harm. 301 and 302 are far more common in the wild for historical reasons, but for anything that isn't a plain page GET, the method-preserving codes are the ones that won't surprise you.
Why permanent vs temporary actually matters
The permanent/temporary split is not just a label. It changes what clients do with the redirect, in two ways that cost real money or traffic if you get them wrong.
Caching. A permanent redirect (301/308) is cacheable by default. A browser that sees 301 from /old to /new can remember it and, the next time you ask for /old, jump straight to /new without even contacting the server. That is great when the move really is permanent. It is painful when it is not, because the cached redirect can stick around for a long time and is hard to undo. A temporary redirect (302/307) is not cached by default, so the client checks with the server every time, which is what you want while the destination might change.
SEO. Search engines treat the two differently, and this is where a wrong code becomes a wrong business decision. A 301/308 tells a search engine "this page moved for good, transfer its ranking and accumulated authority to the new URL." A 302/307 says "the original is still the real page, this detour is temporary, keep crediting the old URL." Use a temporary redirect for a move that was actually permanent and you can lose the ranking you spent years building, because the search engine keeps pointing at a URL you have abandoned. This is the single most common redirect mistake, and the fix is simply choosing the code that matches reality.
The mental shortcut: permanent is a promise. Only make it when you mean it, because caches and search engines will hold you to it.
The two redirects almost every site runs
In production you will set up the same two redirects over and over, because they are how a site presents one canonical address to the world.
http → https. A visitor who types http://example.com should not be served over an insecure connection. The standard pattern is a tiny server whose only job is to listen on port 80 and redirect everything to the https:// version. On Nginx that looks like:
server {
listen 80;
server_name example.com www.example.com;
return 301 https://example.com$request_uri;
}
nginx
$request_uri carries the original path and query along, so http://example.com/blog?page=2 lands on https://example.com/blog?page=2, not just the homepage. This is the redirect that fired on the very first line of our curl chain earlier.
www → non-www (or the reverse). A site usually wants one canonical hostname, not two that serve identical content, because duplicate URLs split your SEO signals and confuse caches. So you pick one, example.com or www.example.com, and permanently redirect the other to it:
server {
listen 443 ssl;
server_name www.example.com;
return 301 https://example.com$request_uri;
}
nginx
Both of these are permanent moves, so they should be 301 (or 308). They are redirecting plain GET page requests, which is the one case where 301 is perfectly safe, which is why 301 is what you see most in the wild. That is exactly the chain you watched against GitHub: http://www.github.com walked through both of these redirects, http→https and www→non-www, before reaching a real page.
The pitfall: redirect loops
The classic redirect bug is the redirect loop: A redirects to B, and B redirects right back to A (or a longer ring that eventually circles home). The browser follows the chain, never reaches a 200, and eventually gives up with an error like ERR_TOO_MANY_REDIRECTS. The page simply never loads.
Loops usually come from two redirect rules that disagree. A common one: a reverse proxy terminates TLS and forwards plain HTTP to your app, but your app has its own "redirect HTTP to HTTPS" rule. The app only sees the plain HTTP it was handed, decides the request is insecure, and redirects to HTTPS, which the proxy terminates back to plain HTTP, which the app redirects again, forever. (This is also where the X-Forwarded-Proto header from the reverse-proxy chapter earns its keep: it lets the app learn the request was originally HTTPS so it stops redirecting.)
The way to see a loop is the same -IL from before, which prints every hop so you can read the whole chain:
curl -IL https://example.com
bash
curl -IL walks the entire chain and prints each status code and Location in order. A healthy chain ends in a 200. A loop shows the same two URLs alternating, and curl stops with Maximum (50) redirects followed. The moment you see the same Location come back around, you have found your loop, and the fix is to make the two rules agree on when a request is already at its final destination.
What's Next
A server can answer a request, route it to the right site, or send the client elsewhere. The next chapter looks at what happens when one server isn't enough: load balancing across many servers, and rate limiting to keep any single caller from overwhelming them.