Anatomy of a Request and Response
Tung Nguyen
10 min read
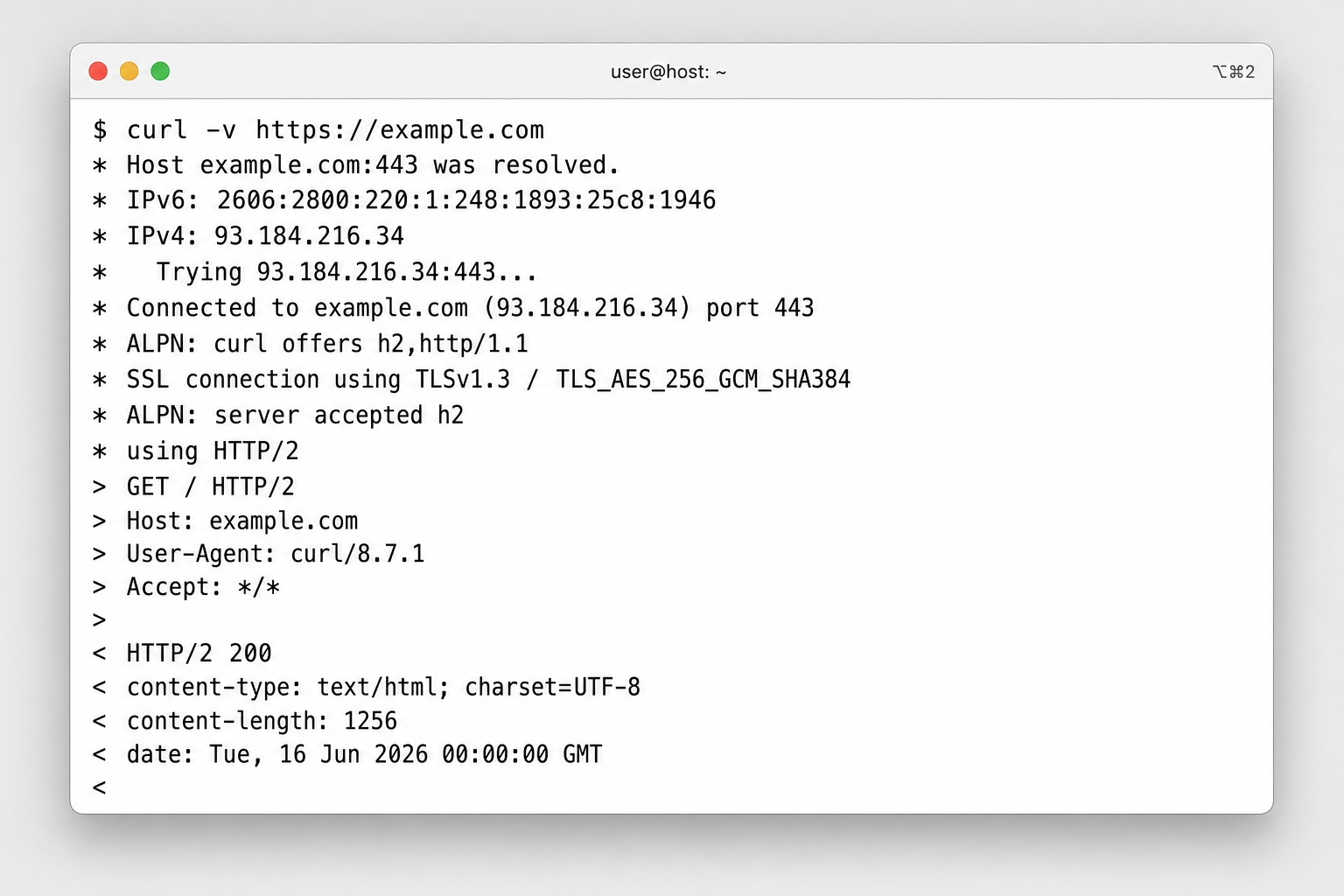
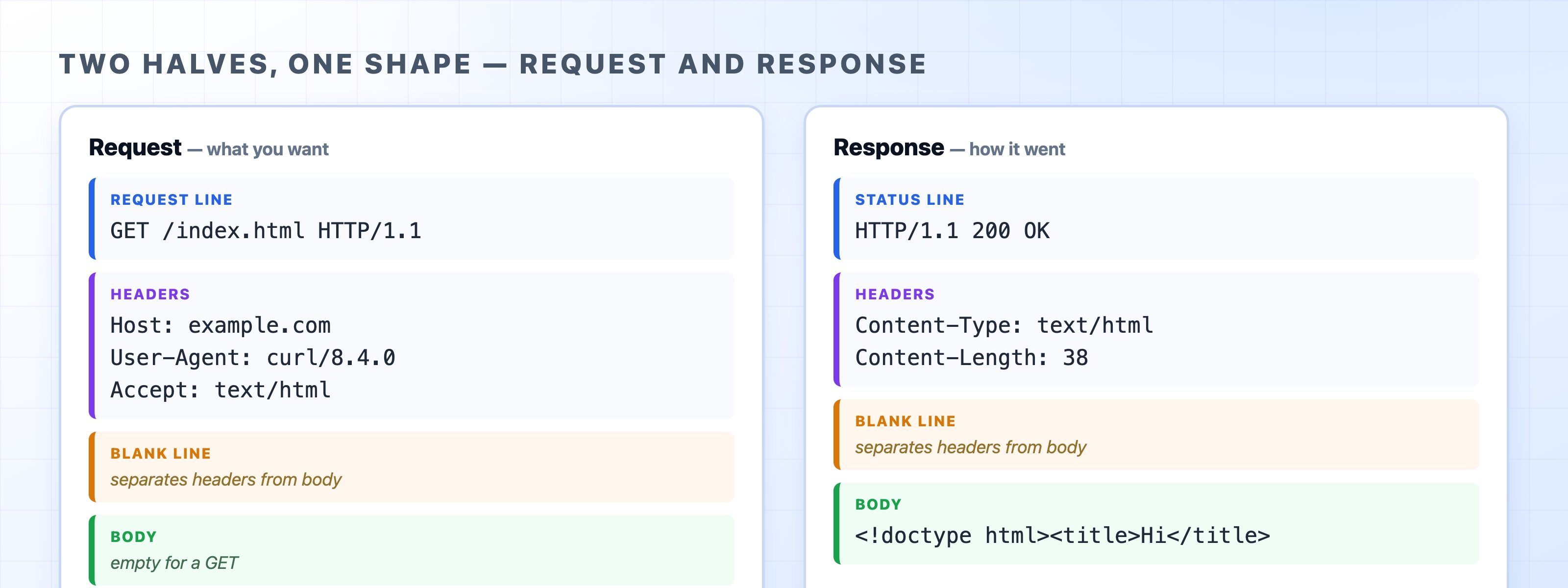
You have already seen that HTTP is a request and a response, and that both are really just lines of text. Now we will slow down and read every line. The good news is that there is very little to memorize. A request and a response share almost the exact same structure. Once you can name the parts of one, you can read the other. If you understand this basic shape, you can read any HTTP message you ever encounter.
The shape of a request
Every request is built from four parts, appearing in a specific order. Here is a complete example:
httpGET /index.html HTTP/1.1Host: example.comUser-Agent: curl/8.4.0Accept: text/html
Reading top to bottom:
- The request line is the very first line. It contains the method, the path, and the HTTP version. The line
GET /index.html HTTP/1.1translates to "fetch the resource at/index.htmlusing HTTP 1.1." This is the line that states exactly what you want the server to do. - The headers are the
Key: Valuelines that follow. They carry extra information about the request, such as which host you are trying to reach, what kind of browser you are using, and what data formats you accept. Each header sits on its own line. - The blank line comes next. It looks like empty space, but it performs a specific job that we will cover in a moment.
- The body follows the blank line. A
GETrequest has no body, which is why the example above ends with the blank line and nothing after it. A request that sends data to the server, like aPOST, puts that data here.