What You Will Build
Tung Nguyen
9 min read
In the last two chapters we talked about Go in the abstract. Now let us look at the thing you will actually build. The whole course points at one project: a Task API, a small web service for managing a to-do list over HTTP. This chapter is a map of that destination, so when we start writing code you already know where each piece fits.
No code here yet. Just the shape of what is coming.
What the Task API does
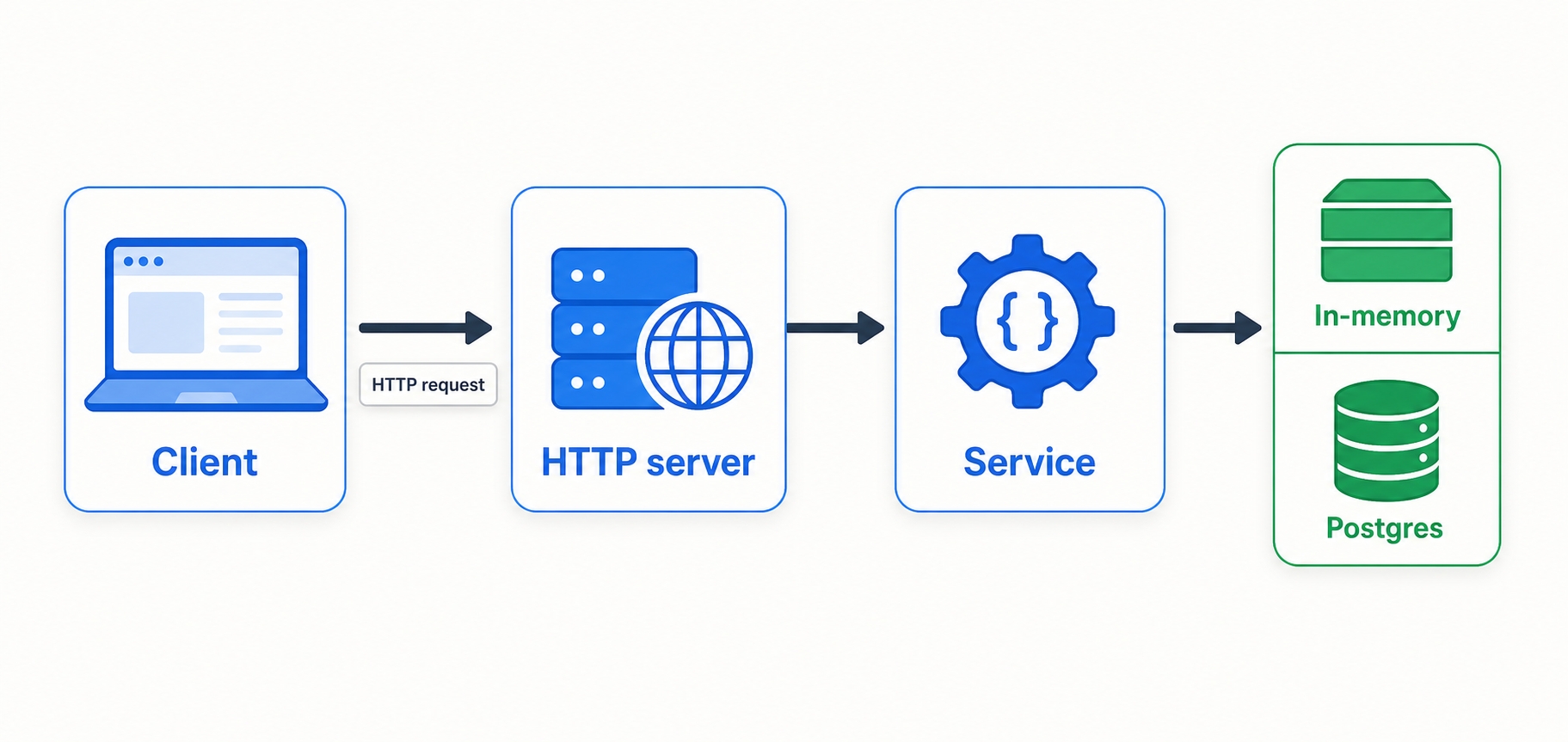
A Task API is a backend service that stores tasks and lets other programs create, read, update, and delete them over the network. There is no website or screen attached to it. It speaks JSON (a plain-text format for sending data) over HTTP (the protocol the web runs on), so anything that can make an HTTP request can use it: a web app, a mobile app, a command-line tool, or you, poking at it with curl.
A single task is simple. It has a title, maybe a longer description, and a flag for whether it is done. That is the entire domain. We deliberately keep it small so the interesting part is never "what does a task mean" but "how do you build a service properly in Go."
Why a to-do list, of all things
A to-do app is the classic beginner project, and for backend work that reputation is earned. Here is what makes it a good teacher.
The domain gets out of your way. You already understand tasks, so no mental energy goes into the problem itself. All of it goes into the code.
It exercises the full set of REST operations. REST is the common style for HTTP APIs, where you act on resources (here, tasks) using a small set of HTTP verbs. A task naturally needs all of them: create one, list them, fetch one, change one, remove one. By the time the API is finished you will have used every verb you are likely to need in real work.
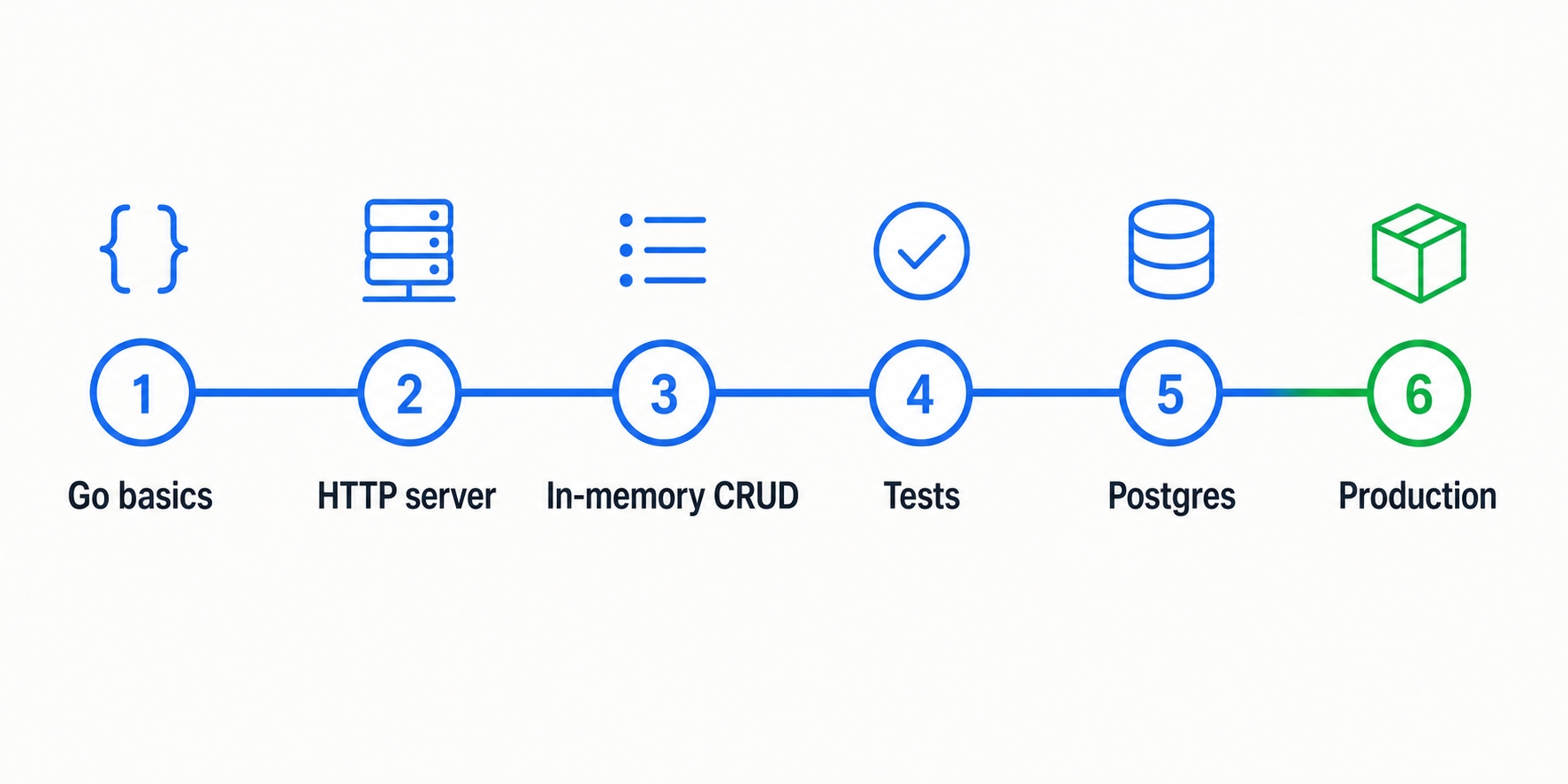
And it grows in exactly the directions a real service does. We start with tasks held in memory, then add validation, then tests, then a real database, then the production trimmings. Each step has an obvious reason to exist, so nothing feels like busywork. The same arc, from "it works on my laptop" to "it is ready to ship," is the arc of most backend projects you will build for real.