In the last chapter, we covered Go's control flow. Now we get to the part that ties everything together. This chapter introduces structs and methods. These are the building blocks Go uses to model data and behavior. We will also cover pointers. Beginners often find pointers confusing at first, but they become second nature with practice. The Task struct you define here is the exact same one we will use throughout the rest of the course, all the way to the database-backed API.
Overview
We are adding two new files. task.go defines the Task struct and its methods. structs.go holds three demo functions that exercise what we just built.
Value receiver copies the Task while pointer receiver mutates the original
By the end of this chapter you will:
Define a struct and create values using struct literals, &Task{}, and new
Attach methods to a type using value and pointer receivers
Understand why mutation requires a pointer receiver
Use pointers safely: take an address with &, read through one with *, and recognize a nil pointer
Check out the finish branch:
git checkout 09-structs-and-methods-finish
bash
What These Terms Mean
Struct. A named collection of fields. Go uses structs the way other languages use classes, but without inheritance. You define the data shape once and attach behavior using methods.
Go Structs Methods and Pointers Explained | dalabs.academy
Method. A function attached to a type. The type it attaches to is called the receiver. You write the receiver between the func keyword and the method name, like this: func (t Task) Summary() string.
Value receiver. The receiver is passed as a copy. The method can read the fields, but any changes made to the copy disappear when the method finishes.
Pointer receiver. The receiver is passed as the memory address of the original value. Changes made here affect the original.
Pointer. A variable that holds a memory address. Writing p := &x makes p point to x. Writing *p reads the value at that address. Go has pointers but no pointer arithmetic. You cannot do p++ to move to the next memory address.
Nil pointer. A pointer that points to nothing. Trying to read a nil pointer causes the program to crash at runtime.
Embedding. Placing one struct type inside another without giving it a field name. The inner type's fields and methods are promoted directly onto the outer type.
The Task struct
This is the struct we will carry through every remaining chapter:
// task.go
type Task struct{
ID int
Title string
Done bool
}
go
It has three fields: an integer ID, a string title, and a boolean that tracks whether the task is finished. It is simple by design. The later API chapters will add more fields, but this core shape stays the same.
Go does not require a constructor function. You can build a Task in three different ways:
All three approaches work. The struct literal gives you full control over the initial values. &Task{} creates a struct and immediately returns a pointer to it. This is very common in Go code. new(Task) also returns a pointer to a struct with default values. It is less common, but worth knowing.
Any fields you leave out of a literal get their zero value automatically (0, "", false). Go calls this zero initialization. You never have to worry about uninitialized memory.
Attaching methods
A method is simply a function with a receiver. The Summary method returns a one-line description of a task:
The (t Task) part is the receiver. When you call literal.Summary(), Go passes a copy of literal into t. The method reads the fields and returns a string. Because it never changes the data, a value receiver works perfectly here.
Value receiver vs. pointer receiver
This is the most important concept in the chapter. It is also the place where beginners usually get stuck.
Look at these two methods side by side:
// task.go
func(t Task)markDoneByValue()bool{
t.Done =true
return t.Done
}
func(t *Task)MarkDone(){
t.Done =true
}
go
markDoneByValue uses a value receiver: (t Task). When you call it, Go copies the Task into t. Setting t.Done = true changes the copy. When the method finishes, that copy is thrown away. The original task in the calling function is never touched.
MarkDone uses a pointer receiver: (t *Task). When you call it, Go passes the address of the original task. Setting t.Done = true writes through the pointer directly to the original. The change sticks.
Here is what the demo in structs.go does to make this visible:
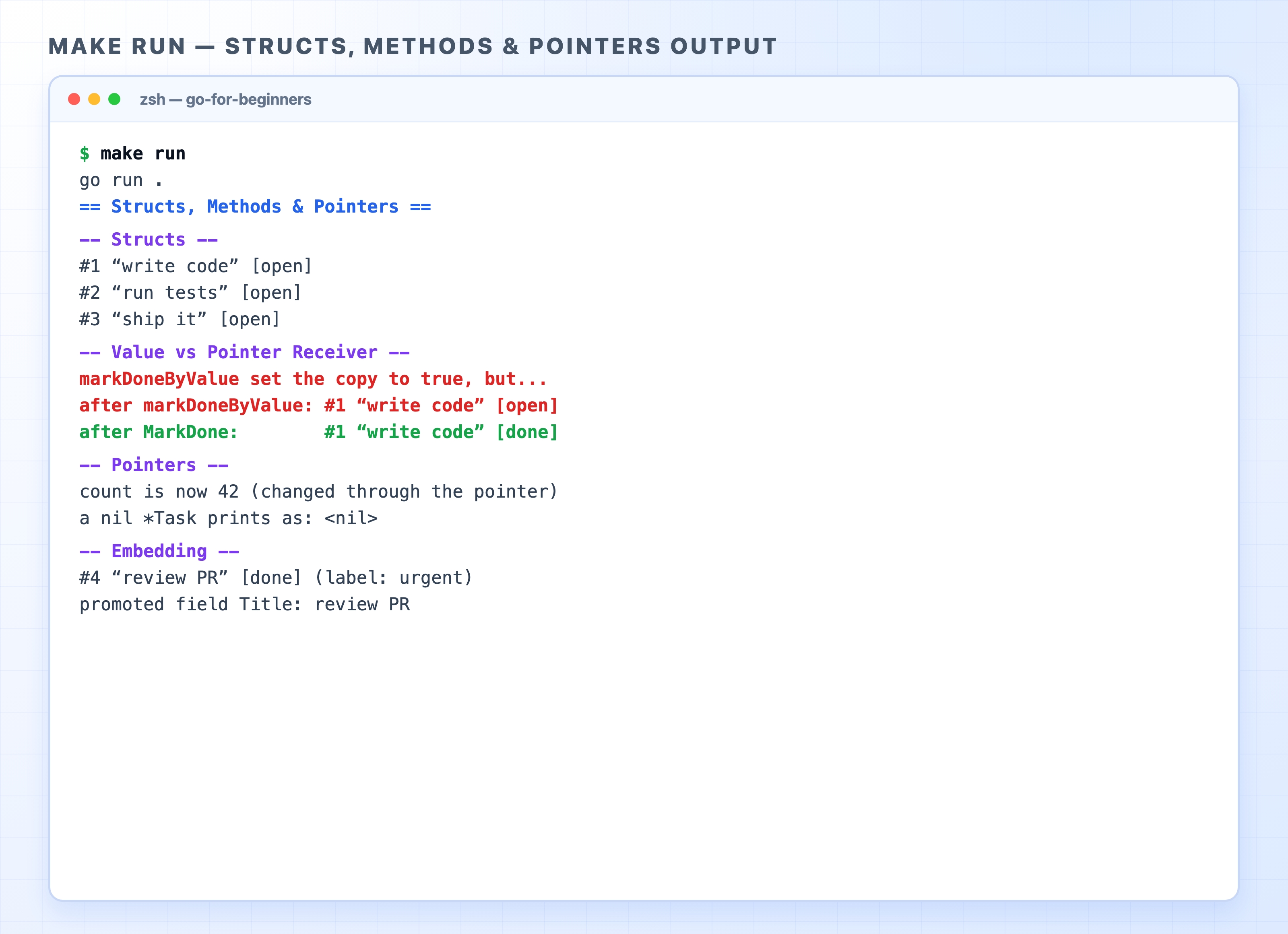
// structs.go
insideCopy := literal.markDoneByValue()
fmt.Printf("markDoneByValue set the copy to %t, but...\n", insideCopy)
make run output for the structs methods and pointers demos
The red lines show that markDoneByValue returned true. The copy really did flip to done, but literal still prints [open]. Then MarkDone runs and literal becomes [done]. Both methods tried to do the same thing, but they had completely different outcomes.
This is a classic beginner mistake. You call a method expecting it to update a struct, but nothing changes. The method worked, but it modified a copy you will never see again.
When to use each
Use a value receiver for read-only methods. Use a pointer receiver when the method needs to modify the struct.
There is also a consistency rule worth knowing. Once a type has a pointer receiver method, it is usually best to make all its methods pointer receivers. Mixing them can lead to surprises later when you use interfaces. The Task type has MarkDone as a pointer receiver, so in real production code, you would make Summary a pointer receiver too. We deliberately mixed them here to show the read-only case side by side with the mutation case.
Pointers
The pointersDemo function shows how pointers work without using a struct at all:
// structs.go
count :=41
p :=&count
*p =*p +1
fmt.Printf("count is now %d (changed through the pointer)\n", count)
var missing *Task
fmt.Println("a nil *Task prints as:", missing)
go
Writing &count takes the address of count and stores it in p. The variable p is now a *int, which means a pointer to an integer. Writing *p reads the value at that address. The line *p = *p + 1 adds one to the value at the address p holds. Because this is the exact same memory as count, count becomes 42.
The second part declares missing as a *Task without assigning it anything. Its zero value is nil. Printing a nil pointer prints <nil>. If you tried to access a field on missing, like missing.ID, the program would crash at runtime. When you work with pointer types, always check for nil before reading their fields.
Go has pointers, but no pointer arithmetic. You cannot write p++ to advance to the next element in memory. This makes Go pointers much safer than pointers in languages like C.
Struct embedding
Go has no class inheritance. Instead, you compose types. Embedding is how you do this. You place one type inside another without giving it a field name.
// structs.go
type labeledTask struct{
Task
Label string
}
go
The labeledTask struct embeds Task. This means labeledTask automatically has ID, Title, Done, and Summary() promoted to it. You can use them directly on a labeledTask value:
Calling lt.Summary() delegates to Task.Summary(). Reading lt.Title reaches directly into the embedded Task. You can still spell it out as lt.Task.Title if you need to be explicit, but the short form is standard.
Embedding is Go's answer to the object-oriented idea of inheritance. However, a labeledTask is not a subclass of Task. It simply contains a Task and gets its behavior promoted. This distinction matters later when you use interfaces. For now, the main takeaway is that embedding lets you extend a type without repeating its fields and methods.
What's Next
Chapter 10 covers slices and maps, the two collections you will reach for constantly. They are also the exact data structures that will back the in-memory task store you build a few chapters later.