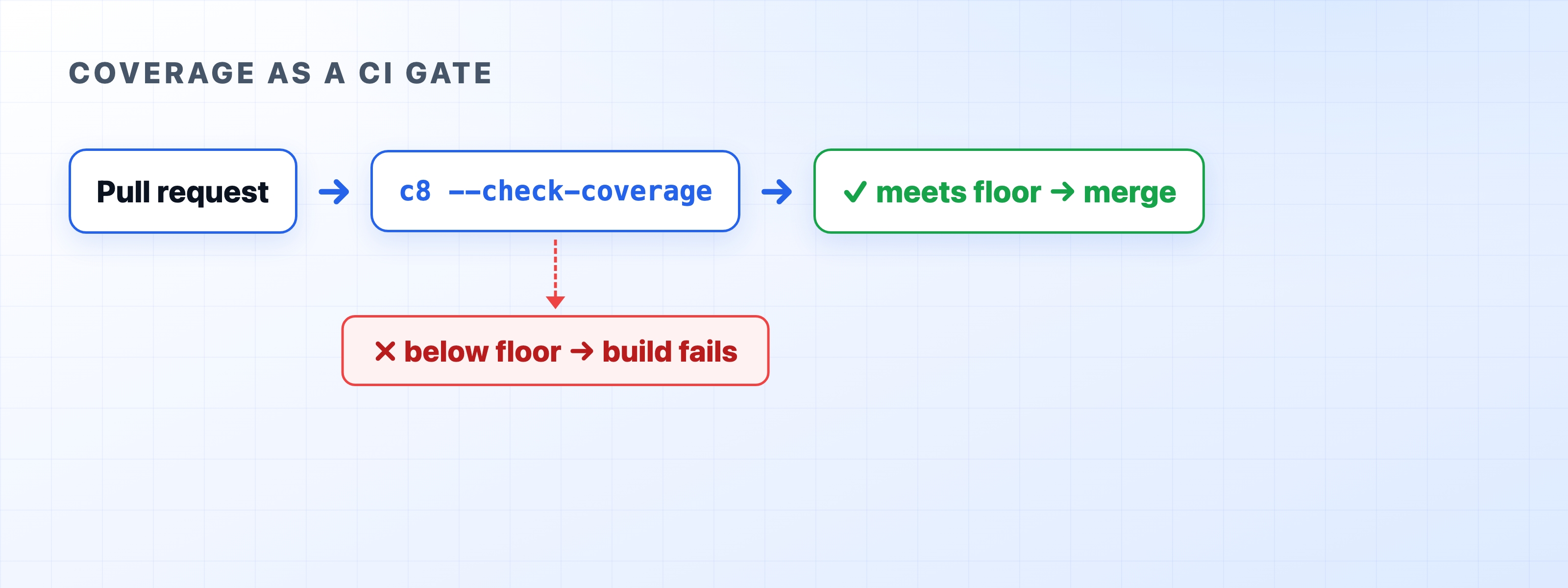
Coverage tells you how much of your code your tests actually run. Here's what that number really means in Node.js, and how to pick a threshold that catches real bugs without chasing 100%.
Sooner or later someone on the team asks for a number. "What's our test coverage?" And then the harder question: how much is enough? Chase 100% and you waste days testing getters and log lines. Ignore it and real bugs slip through untested branches. Test coverage in Node.js is a useful signal, but only if you understand what it actually counts and where it stops being meaningful.
The short version: aim for coverage on the code that would hurt if it broke, set a floor your CI enforces, and stop treating the percentage as the goal. The longer version is worth your time, because the wrong target quietly trains a team to write bad tests.
What these terms mean
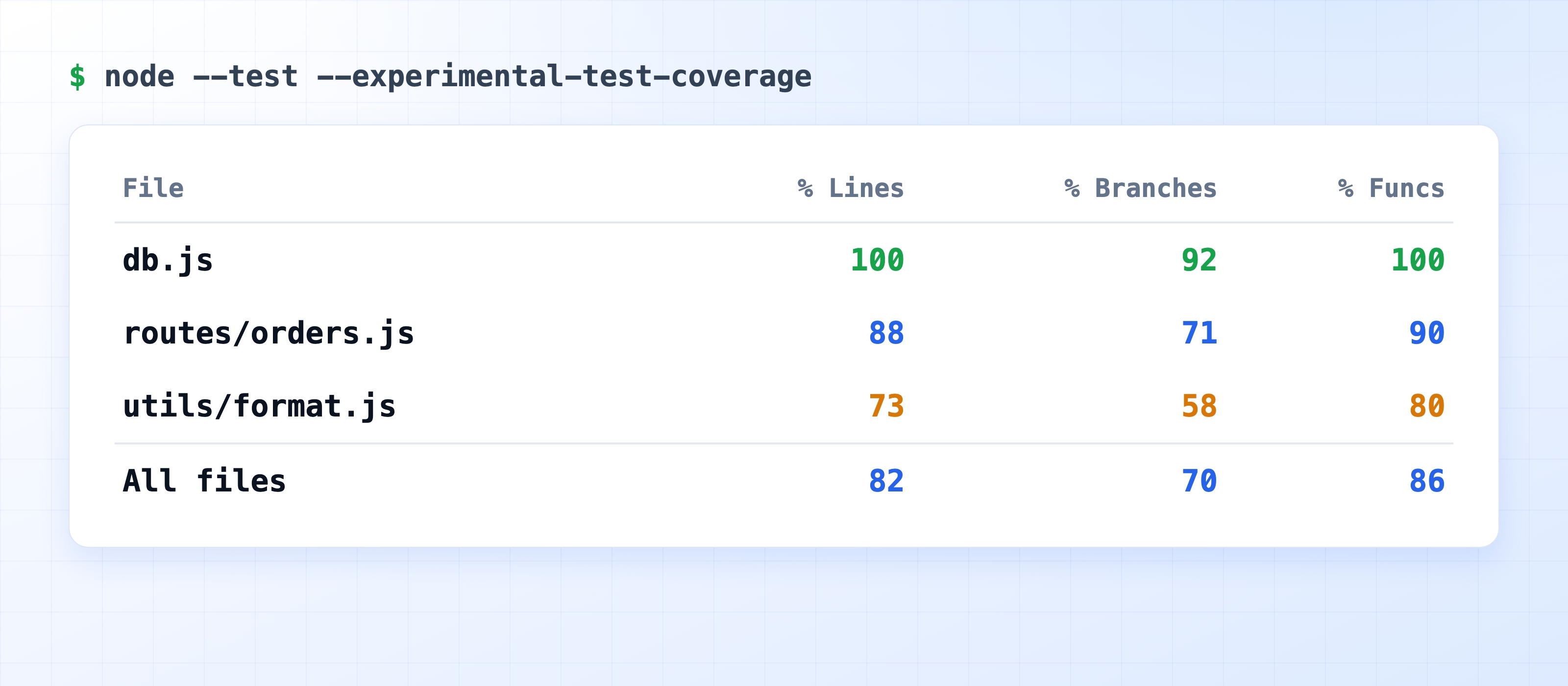
Line coverage is the percentage of executable lines that ran at least once during your tests. It's the number most people quote, and also the easiest to game.
Branch coverage is the percentage of decision paths that were taken — both the if and the else, both sides of a ternary, every case. This is the number that actually tells you something, because most bugs live in the branch you forgot to test.
The coverage tool instruments your code, runs the tests, and records which lines and branches executed. Node.js ships one in its built-in test runner via ; the standalone tool wraps the same V8 coverage data and produces richer reports.