A graceful shutdown lets your app finish its current work before it exits, so deploys stop dropping requests. It's a few lines of code that turn a stream of 502s into clean rolling releases.

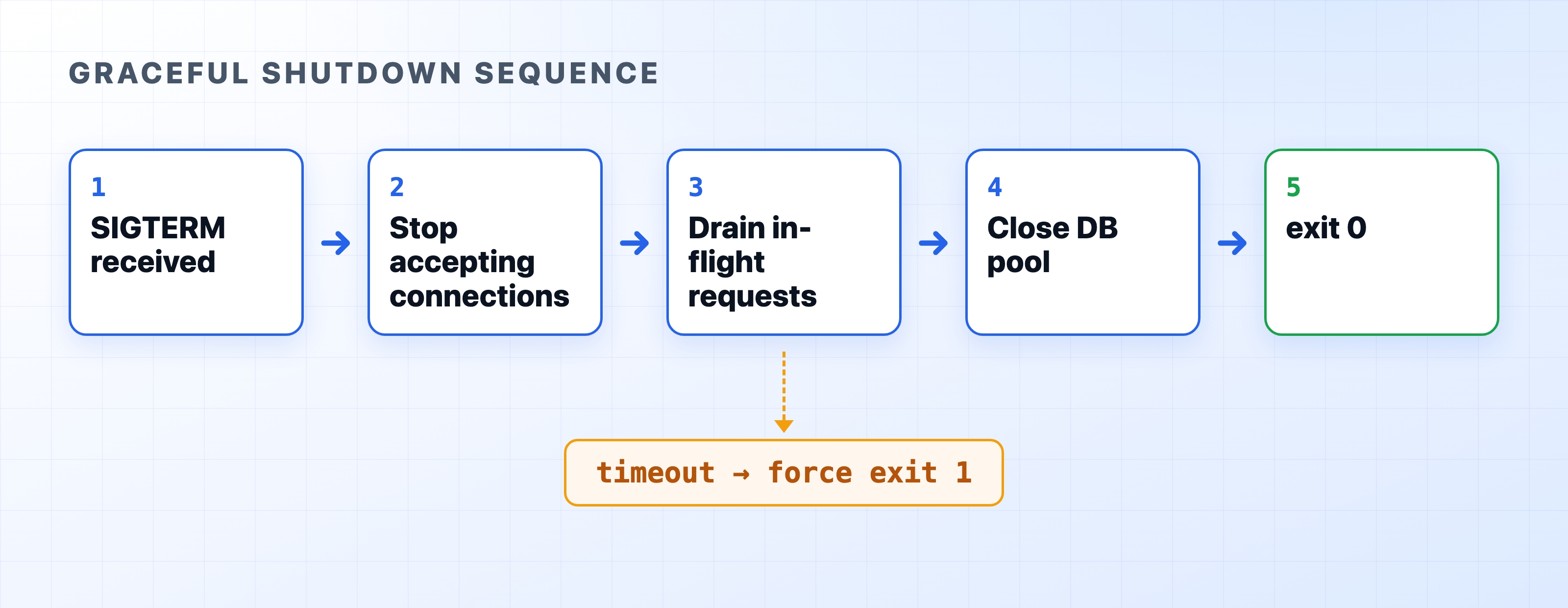
Here's the problem. Every time you deploy, your orchestrator kills the old version. If your Node.js process exits the second it's told to, any request still running gets cut off and any open database transaction is abandoned. A graceful shutdown fixes that: the process stops taking new work, finishes what it started, releases its resources, then exits.
Most tutorials skip this. You wire up routes, connect a database, ship it, and never think about how the process stops. Then you move to Docker or Kubernetes and find your "zero-downtime" deploys drop a few requests every single time.
What these terms mean
SIGTERM is the signal a process manager sends to ask your app to shut down. Docker sends it on docker stop, Kubernetes sends it before evicting a pod, and most deploy steps send it to the old instance. By default, Node.js reacts by exiting right away. You get a few seconds (Kubernetes gives 30) before it escalates to SIGKILL, which can't be caught and kills the process instantly.
Draining means letting in-flight requests finish while turning new ones away. The server stops accepting new connections but keeps the existing ones alive until their responses go out. Once the last one finishes, there's nothing left to interrupt.
Why immediate exit hurts
A process that dies on contact loses three things at once.
In-flight requests die with it. A user halfway through checkout gets a connection reset instead of a response. Behind a load balancer doing rolling deploys, this happens on every release.