Last chapter, IP got our packets to the right machine. But IP makes no promises once they leave: a packet can vanish, arrive twice, or show up out of order, and IP will shrug and move on. HTTP can't work like that. It expects to write a request and read back a clean response, byte after byte, in the right order. The layer that turns IP's best-effort delivery into that orderly stream is TCP, and this chapter is about how it pulls that off.
Overview
TCP, the Transmission Control Protocol, sits between IP and HTTP. Its job is to take the unreliable, unordered packets IP delivers and present HTTP with a reliable, ordered stream of bytes. Before any of that data flows, the two sides perform a short opening ritual called the three-way handshake.
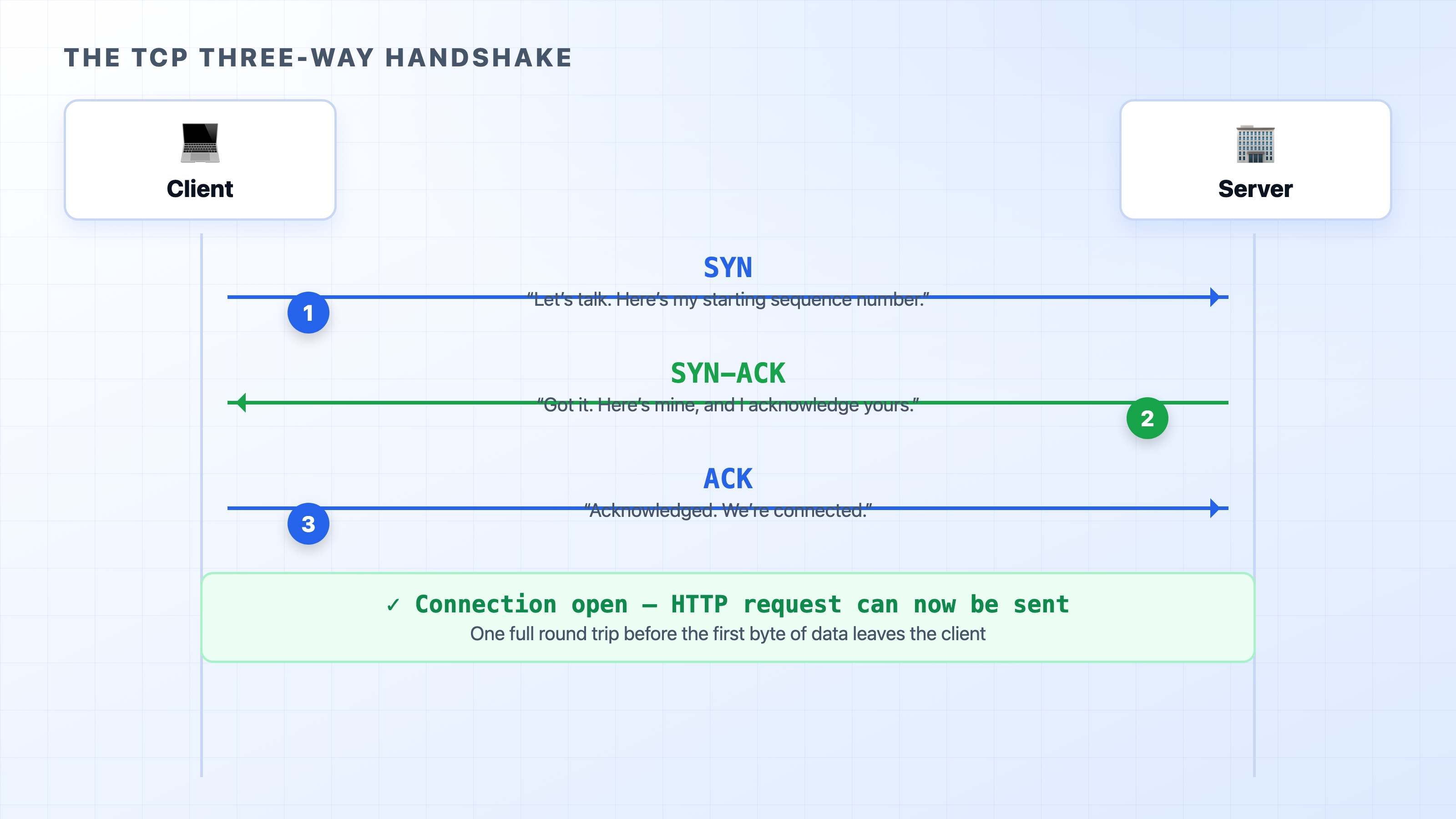
The SYN SYN-ACK ACK three-way handshake between client and server
Here is what we will cover:
The three-way handshake that opens every TCP connection, and what each step settles
How TCP guarantees order and recovers lost data, in plain terms
Why opening a connection costs a round trip, and what that means for performance
Why HTTP needs more than IP
Picture IP on its own. You hand it a chunk of data, it slaps an address on it and sends it toward the destination. It does its best. But "best effort" is the official description, and it means exactly what it sounds like: a packet might get dropped when a router is overloaded, two packets might take different paths and arrive in the wrong order, and IP will not tell anyone or try again.
A web page cannot tolerate that. If you request an HTML document and the middle third goes missing, you do not want a broken page. If the bytes arrive shuffled, the JSON you parse is garbage. HTTP is written as if it is reading from a clean, gap-free stream, the same way you read a file from start to finish. Something has to provide that stream on top of IP's chaos, and that something is TCP.
So TCP makes HTTP three promises that raw IP does not:
Delivery. Every byte you send arrives, even if it takes a few tries.
Order. Bytes come out the far end in the same order you put them in.
TCP for HTTP Developers: The Handshake Explained | dalabs.academy
A connection. Both sides agree they are talking before any data moves, so each can keep track of the conversation.
The rest of the chapter is really just those three promises, explained.
The three-way handshake
TCP is connection-oriented, which means the two computers establish a shared understanding before sending any real data. They have to agree that they are both there, both listening, and ready to start counting bytes. They reach that agreement with an exchange of three small messages, which is why it is called the three-way handshake.
Each message in TCP is carried in a segment, TCP's unit of data. A segment has a small header with control flags and bookkeeping numbers, and usually some of your actual bytes. During the handshake the segments carry no application data at all. They only carry the flags that set the connection up.
Walk through the three steps, following the diagram above.
Step 1 — SYN. The client sends a segment with the SYN flag set. SYN is short for "synchronize." This is the client saying "I'd like to open a connection, and here is the starting number I'll use to count my bytes." That starting number matters more than it looks, and we will come back to it in a moment.
Step 2 — SYN-ACK. The server replies with a segment that has both SYN and ACK set. ACK is short for "acknowledge." In one message the server is doing two things: acknowledging the client's SYN ("got your request to connect"), and sending its own SYN ("and here is the starting number I'll count from"). Both directions of the conversation get set up at once.
Step 3 — ACK. The client sends a final segment with just the ACK flag, acknowledging the server's SYN. Now both sides have confirmed they can hear each other and both know where the other's byte count begins.
After that third message, the connection is open and HTTP can send its request. Three messages, and the conversation is live.
A common point of confusion: people ask why it takes three steps instead of two. The reason is that a connection has two directions, and each direction has to be confirmed independently. Step 1 and step 2 establish that the server can hear the client. Step 2 and step 3 establish that the client can hear the server. You cannot collapse it into two messages without leaving one direction unconfirmed.
How TCP keeps bytes in order
That "starting number" each side announces in the handshake is the key to ordering. Every byte TCP sends is tagged with a sequence number, a running counter that increases as the stream goes on. The handshake is where both sides agree on where their counters start, so from then on every byte has a position the other side can check.
Now reordering is easy to fix. IP might deliver segment 3 before segment 1, but each segment's sequence number says exactly where its bytes belong in the stream. The receiving TCP holds segments in a buffer and reassembles them in sequence-number order before handing the bytes up to HTTP. HTTP never sees the scramble. It reads a clean, in-order stream, even though the network underneath delivered the pieces in whatever order it pleased.
TCP reorders scrambled segments and resends a lost one
How TCP recovers lost data
Sequence numbers also power the other half of reliability: getting back data that never arrived.
When TCP receives segments, it sends back acknowledgements, those ACK messages again, telling the sender "I've received everything up to byte N." This is the receiver's running receipt. The sender keeps a copy of everything it has sent but not yet seen acknowledged, so it can resend if needed.
If a segment is lost in the network, no acknowledgement comes back for it. The sender waits a short while, and if the ACK still has not arrived, it assumes the segment was lost and sends it again. This is retransmission. From HTTP's point of view nothing happened; the bytes just took a moment longer to arrive. Underneath, TCP quietly noticed the gap and filled it.
The same mechanism handles duplicates and corruption. Each segment carries a checksum, so a corrupted segment is detected and discarded, then retransmitted like any lost one. A duplicate that arrives because of a stray retransmission is recognized by its sequence number and thrown away. The stream HTTP reads stays correct through all of it.
For now, the mental model is: TCP numbers everything, the receiver acknowledges what it got, and anything that goes unacknowledged gets sent again. The real algorithms for timing retransmissions and pacing the sender are more involved than this, but this picture is enough to reason about HTTP correctly.
The handshake costs a round trip
Reliability is not free, and the cost worth knowing about is time.
Before the client can send a single byte of an HTTP request, the handshake has to finish. Look at the steps again: the client sends SYN, waits for the server's SYN-ACK to come back, then sends ACK. The SYN going out and the SYN-ACK coming back is one full round trip, the time for a message to travel to the server and a reply to return. Only after that can the request go out.
A round trip is pure waiting, and it is governed by distance. If the server is across the city, a round trip might be a handful of milliseconds. If it is on another continent, it can easily be 100 to 200 milliseconds. None of that is the server doing work. It is just signals traveling and coming back, and you pay it once to open each new TCP connection.
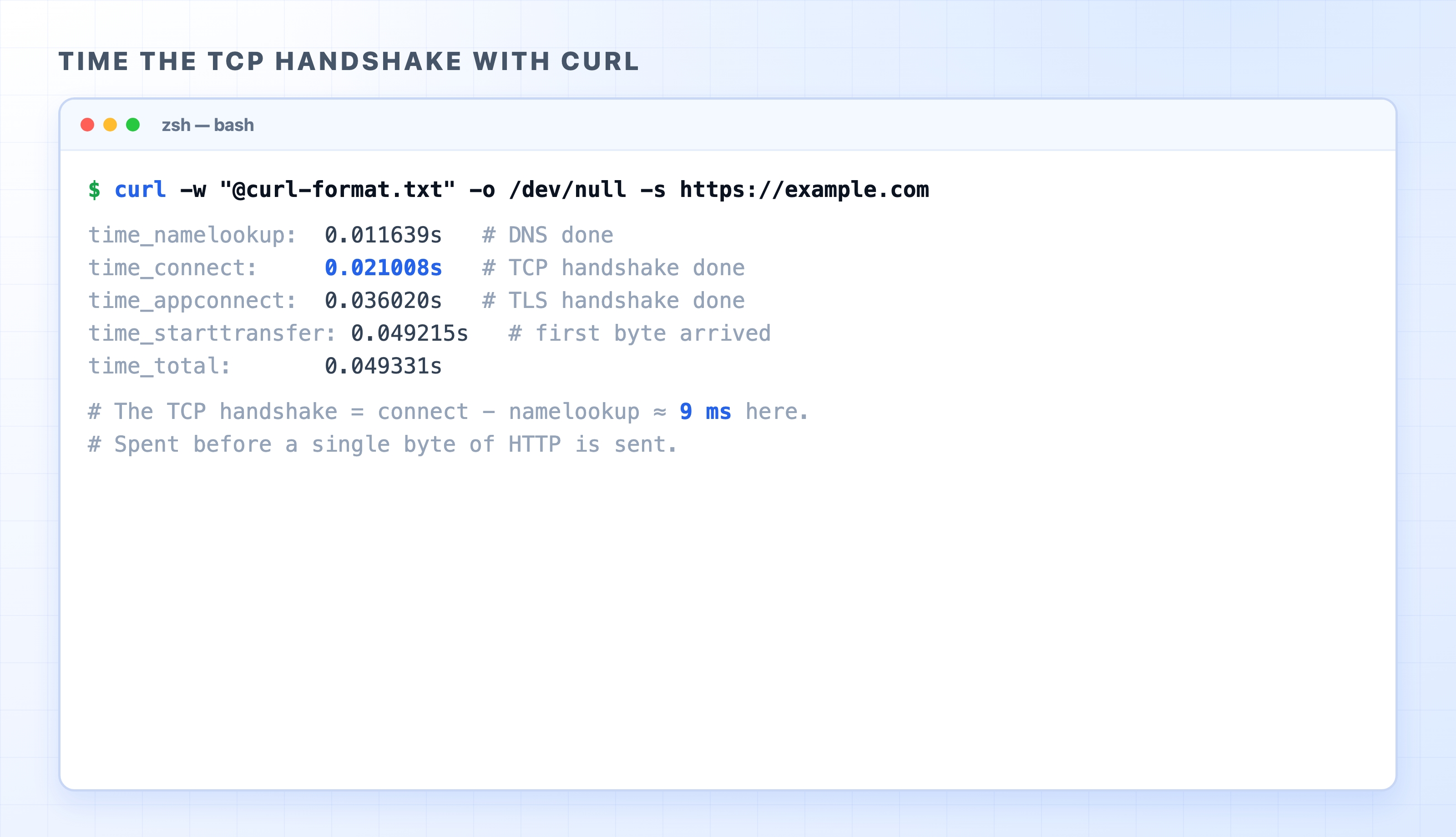
You can watch this cost directly with curl. The -w flag prints timing for each phase of a request. First save this format into a file named curl-format.txt:
curl timing showing the TCP handshake before the first byte
Read the numbers from the top down, because they are cumulative timestamps from the start of the request. time_namelookup is when DNS finished. time_connect is when the TCP handshake finished. The gap between those two, about 9 milliseconds here, is the handshake itself: the round trip that opened the connection, paid before any HTTP went out. (time_appconnect is the TLS handshake, which we will cover in the section on HTTPS; ignore it for now.)
Nine milliseconds is cheap because example.com happened to be close. To a server farther away it would be a much larger slice. And the important part is that you pay it for every new connection. Open ten connections to load a page and you have paid that round trip ten times before any content arrives.
That cost is exactly why later chapters care so much about not opening connections you do not have to. Keeping a connection open and reusing it for several requests, instead of handshaking again each time, is one of the biggest performance wins in HTTP. We will dig into connection reuse and how HTTP/1.1, HTTP/2, and HTTP/3 handle it in the chapter on HTTP versions.
A quick word on TCP versus UDP
TCP is not the only transport on top of IP. Its main counterpart is UDP, the User Datagram Protocol, and the contrast makes TCP's design clearer.
UDP is the opposite trade-off. It has no handshake, no sequence numbers, no acknowledgements, and no retransmission. You hand it a packet and it sends it, with no promise it arrives or arrives in order. That sounds worse, but for some jobs it is exactly right. A live video call or a game would rather drop a late packet than wait for TCP to retransmit it, because by the time the missing data arrives it is already stale. Speed and low latency matter more than perfect delivery.
For most of the web, though, you want every byte and you want them in order, so HTTP/1.1 and HTTP/2 run over TCP. The interesting twist is HTTP/3, which runs over a newer protocol called QUIC that is built on UDP. QUIC rebuilds reliability and ordering itself, in a way that avoids some of TCP's limitations. We will get to why that helps in the chapter on HTTP versions; for now, just know that "HTTP needs reliability" and "HTTP must use TCP" are two different statements, and HTTP/3 is the proof.
What's Next
We now have a reliable, ordered connection between two machines. The next chapter looks at ports and sockets, which let one machine hold many of these connections at once and route each one to the right program.