Content-Type and Content Negotiation | dalabs.academy
Content-Type and Content Negotiation
Tung Nguyen
··
11 min read
For the last several chapters the body has mostly sat in the background. We learned how a request finds the right server, rides over an encrypted connection, and carries credentials that prove who you are. None of that says anything about what is actually in the body, or how the receiving side is supposed to read it. A response is, at the end, just a pile of bytes. The same bytes could be a web page, a chunk of JSON, or a PNG image. Something has to say which.
That something is the Content-Type header. And once a body can take many forms, a useful question follows: if one URL can hand back HTML or JSON or a PDF, how does the client say which one it wants? That second half is called content negotiation. This chapter covers both.
The body is just bytes until a header says otherwise
Open any HTTP response and you will find a header that looks like this near the top:
Content-Type: text/html; charset=utf-8
http
Content-Type is the label on the package. It tells the receiver how to interpret the bytes that come after the blank line. Strip that header away and the body becomes a mystery: a browser would have to guess whether it is looking at a page to render, data to parse, or a file to save. The header removes the guesswork.
The value has two parts. The first is a MIME type (sometimes called a media type): a short, standardized string that names the format, like text/html or application/json. The second, after the semicolon, is an optional parameter that adds detail. The most common one is charset, which we will come back to. For now, focus on that first token, because it is what changes how software behaves.
What a MIME type looks like
A MIME type is always two words joined by a slash: a general type and a specific subtype.
The pattern is readable once you see it. text/* is human-readable text, image/* is a picture format, application/* is "data meant for a program." That last bucket is broad on purpose, which is why JSON, JavaScript, PDFs, and raw binary all live under application.
The name "MIME" comes from email (Multipurpose Internet Mail Extensions), which needed a way to attach non-text parts to a message. HTTP borrowed the same labeling system, so the type names you see on the web are the same ones email has used for decades.
Why the type changes what the browser does
Here is the part worth slowing down on, because it is where Content-Type stops being trivia and starts having visible consequences. A browser does not decide what to do with a response by looking at the URL or the file extension. It looks at the Content-Type header, and it behaves very differently depending on what it finds.
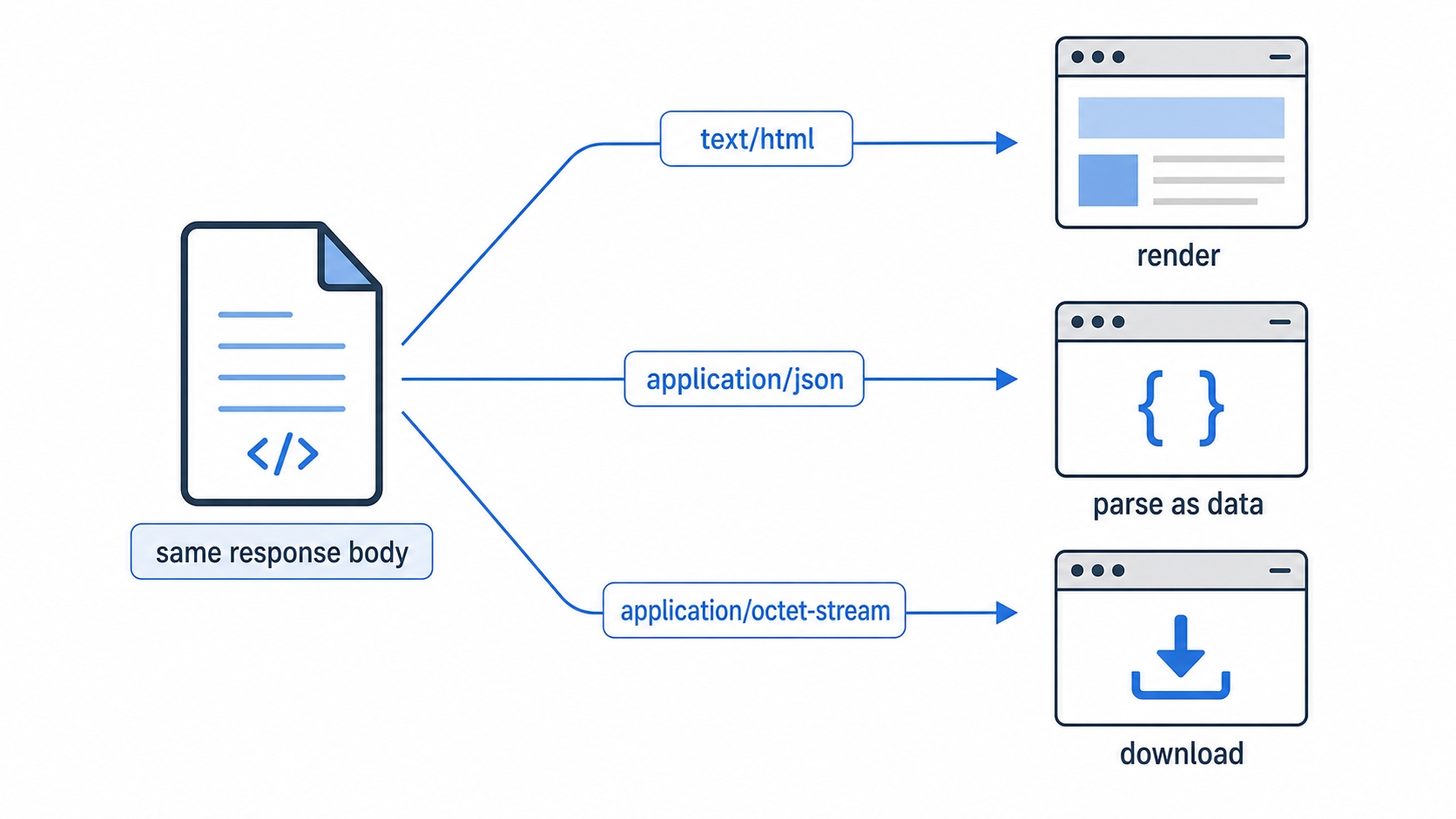
How the browser treats the same bytes based on Content-Type
Take the exact same body of text and send it three times with three different types:
Send it as text/html, and the browser renders it. It parses the bytes as HTML, builds a page, and shows it.
Send it as application/json, and the browser does not render anything. It treats the bytes as data. Code that called fetch will parse it into an object; if you open the URL directly, you usually see the raw text or a data viewer.
Send it as application/octet-stream, and the browser downloads it. It has no idea how to display "unknown binary," so it saves the file to disk instead.
The bytes never changed. Only the label did. This is why a misconfigured Content-Type causes such confusing bugs. If a server sends your JavaScript file as text/plain instead of application/javascript, the browser refuses to run it as a script. If it sends an HTML page as text/plain, you see the raw <html> tags on screen instead of a rendered page, because you told the browser "this is just text, do not parse it."
A common confusion. The file extension in the URL (.json, .png) is for humans, not the browser. The browser trusts the Content-Type header, not the extension. A file named data.json served with Content-Type: text/html is treated as HTML. The header wins.
There is one wrinkle worth knowing. When a server sends a type that looks wrong, browsers historically tried to "sniff" the real type by peeking at the bytes. This was a security problem, since an uploaded "image" that was secretly HTML could get rendered and run scripts. Modern servers usually send X-Content-Type-Options: nosniff to switch that guessing off and force the browser to trust the declared type. The practical lesson stays the same: set the right Content-Type and you avoid the whole mess.
The charset parameter, and why UTF-8 is the safe default
Back to that second part of the header. For text formats, the bytes alone do not fully describe the content, because a byte like 0xE9 could mean different characters depending on the character encoding in use. The charset parameter names that encoding so the receiver decodes the bytes into the right characters.
UTF-8 is the encoding to reach for, and in practice it is the default across the modern web. It can represent every character in Unicode, which covers essentially every written language plus emoji, and it stays compact for plain English text. Sending charset=utf-8 (and actually encoding your text as UTF-8) is the safe choice that avoids the garbled-character class of bug almost entirely. If you are ever unsure what to set, UTF-8 is the answer.
A small note for completeness: JSON is defined to be UTF-8, so application/json does not carry a charset parameter. The charset really matters for text/* types and for HTML forms, where older encodings still lurk.
One URL, many representations
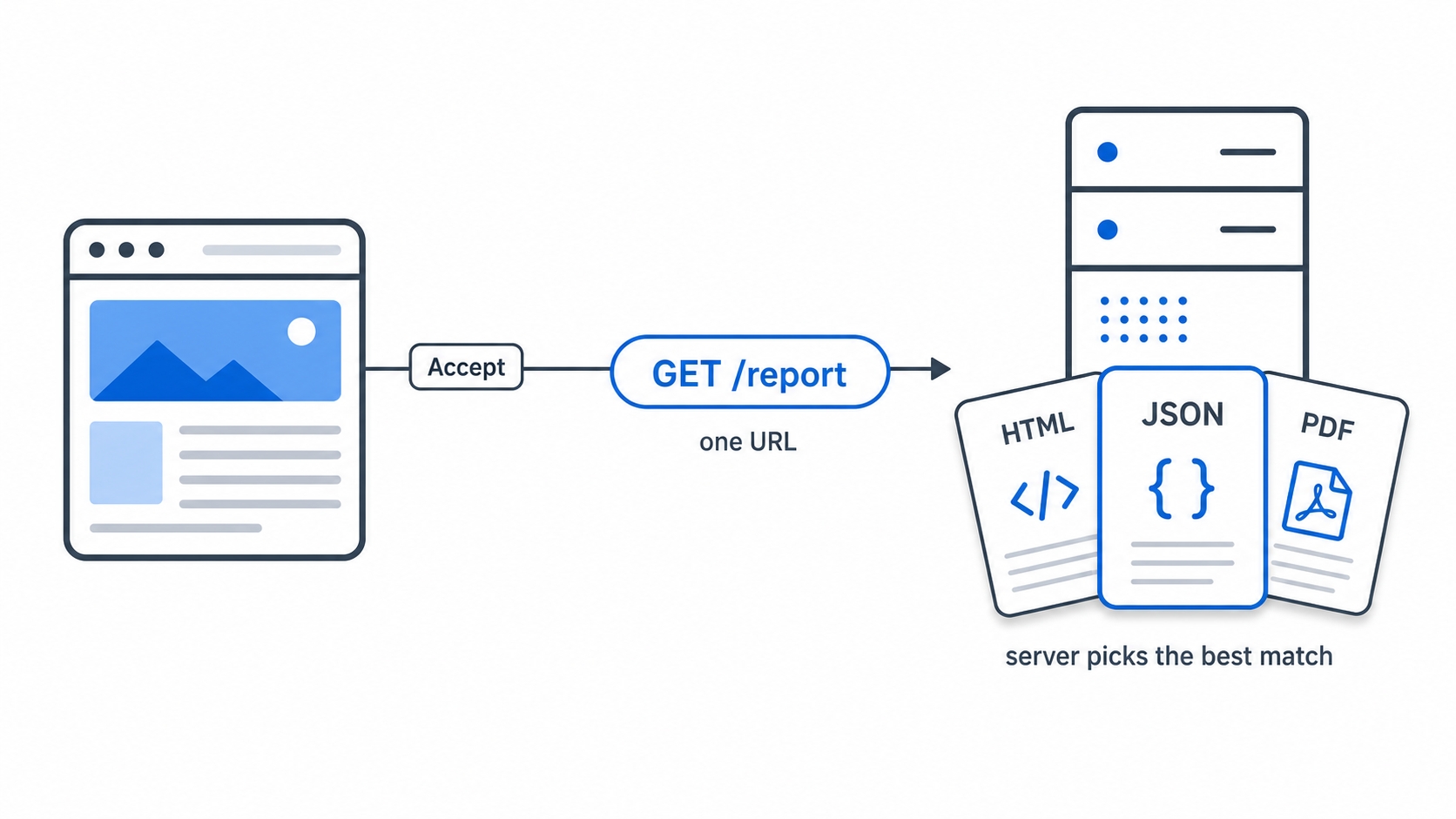
So far the server has decided the format on its own. But the same resource can sensibly exist in more than one form. A report at /reports/q3 might be available as a web page for a person, as JSON for a script, and as a PDF for printing. They are all "the Q3 report," just different representations of it.
This is where the design gets interesting. Instead of inventing three URLs (/reports/q3.html, /reports/q3.json, /reports/q3.pdf), HTTP lets you keep one URL and let the client and server negotiate which representation comes back. That mechanism is called content negotiation.
One URL many representations chosen by the Accept header
The client states its preferences in a set of request headers, all beginning with Accept:
Accept says which MIME types the client can handle: "I would like JSON, but HTML is fine too."
Accept-Language says which human languages it prefers: "English first, then French."
Accept-Encoding says which compression formats it understands, like gzip or br. We give that header a full chapter of its own next, on compression.
The server reads these, picks the representation it thinks fits best, sends it, and crucially, sets Content-Type (and Content-Language, and Content-Encoding) on the response to report exactly which one it chose. The request says "here is what I would like"; the response says "here is what you got." Negotiation is a request, not a command. The server makes the final call, and it might not have your first choice available.
Your browser already does this on every page load without you noticing. A typical browser request carries something like:
That is the browser quietly announcing, on your behalf, the formats, languages, and compression it can deal with. The server takes it from there.
Reading quality values
Look again at the language header above and you will spot a piece of syntax we have not explained: en;q=0.9. That q is a quality value, and it is how a client expresses ranked preferences instead of a flat list.
A quality value is a number from 0 to 1 attached to an option with ;q=. Higher means "I prefer this more." Anything listed without an explicit q is treated as q=1.0, the top rank. So this header:
Accept-Language: en-US,en;q=0.9,fr;q=0.7
http
reads as a ranked wish list:
Option
Quality
Meaning
en-US
1.0 (implied)
US English, most preferred
en
0.9
Any English, almost as good
fr
0.7
French, acceptable if no English exists
The server walks its available representations, scores each against this list, and returns the highest-scoring one it can actually produce. If the report only exists in French and German, neither en-US nor en matches, so French wins at 0.7. A value of q=0 is special: it means "I do not want this one at all," a way to explicitly rule an option out.
The same q syntax works in Accept for MIME types. Accept: application/json;q=1.0, text/html;q=0.5 says "JSON if you have it, HTML only as a fallback." Conceptually the server is just sorting your options by quality and handing back the best match it has on the shelf.
Worth keeping in perspective. Many real servers do not implement the full ranking algorithm, and some ignore these headers entirely and always return one format. Content negotiation is a mechanism HTTP offers, not a guarantee every server honors. The mental model, though, holds everywhere: the client ranks what it wants, and the server tries to oblige.
Try it now
Let's watch negotiation actually happen. The httpbin.org service has an endpoint that mirrors back details about your request, and you can change a single header to change what comes back. Pass a header to curl with -H, and read the response.
Negotiating JSON vs HTML from one endpoint with curl
To see the type the server actually chose, ask for the response headers only with -I and look for the Content-Type line:
curl -I https://httpbin.org/image/png
bash
That last one reports Content-Type: image/png, which is the server telling you "these bytes are a PNG." Finally, prove the misconfigured-type bug to yourself: open https://httpbin.org/html in a browser and it renders as a page, because it arrives as text/html. The same content described as text/plain would show up as raw tags. One header, completely different behavior.
What's Next
You now know how the body announces its format and how the two sides agree on which representation to exchange. Next we zoom in on one of those Accept headers, Accept-Encoding, and see how gzip and brotli shrink a response on the wire without changing what it means.