HTTP Compression: gzip and Brotli Explained | dalabs.academy
Compression
Tung Nguyen
··
11 min read
In the last chapter we met three Accept headers the browser sends on every request. Two of them, Accept and Accept-Language, choose which representation comes back. The third, Accept-Encoding, is different. It does not change what the body says at all. It changes how many bytes it takes to say it. This chapter is about that header and the compression it switches on.
The payoff is large and almost free. A 281 KB stylesheet can cross the wire as 33 KB, and the browser unpacks it back to the exact same 281 KB before any code ever sees it. Same content, a fraction of the transfer. Let's see how the two sides agree to do that, which compression methods they use, and where the squeezing should actually happen.
What compression does here
Compression in HTTP means the server runs the response body through an algorithm that rewrites it in fewer bytes, sends the smaller version, and the client reverses the process to recover the original. The body the browser ends up with is byte-for-byte identical to the uncompressed one. Nothing about the meaning changes. Only the size on the wire does.
The reason this works is that text is full of repetition. An HTML page repeats <div, class=, and the same handful of CSS class names hundreds of times. A JSON response repeats every key on every object. Compression algorithms are very good at spotting that repetition and storing it once instead of a thousand times. That is why the same trick that shrinks a stylesheet by 8x does almost nothing to a photo, a point we will come back to.
This is content encoding, and it is worth separating from the Content-Type you learned last chapter. The type says what the bytes are (HTML, JSON, an image). The encoding says how those bytes were packed for transport. A response can be Content-Type: text/html and at the same time. It is an HTML document, currently wearing a gzip wrapper for the trip.
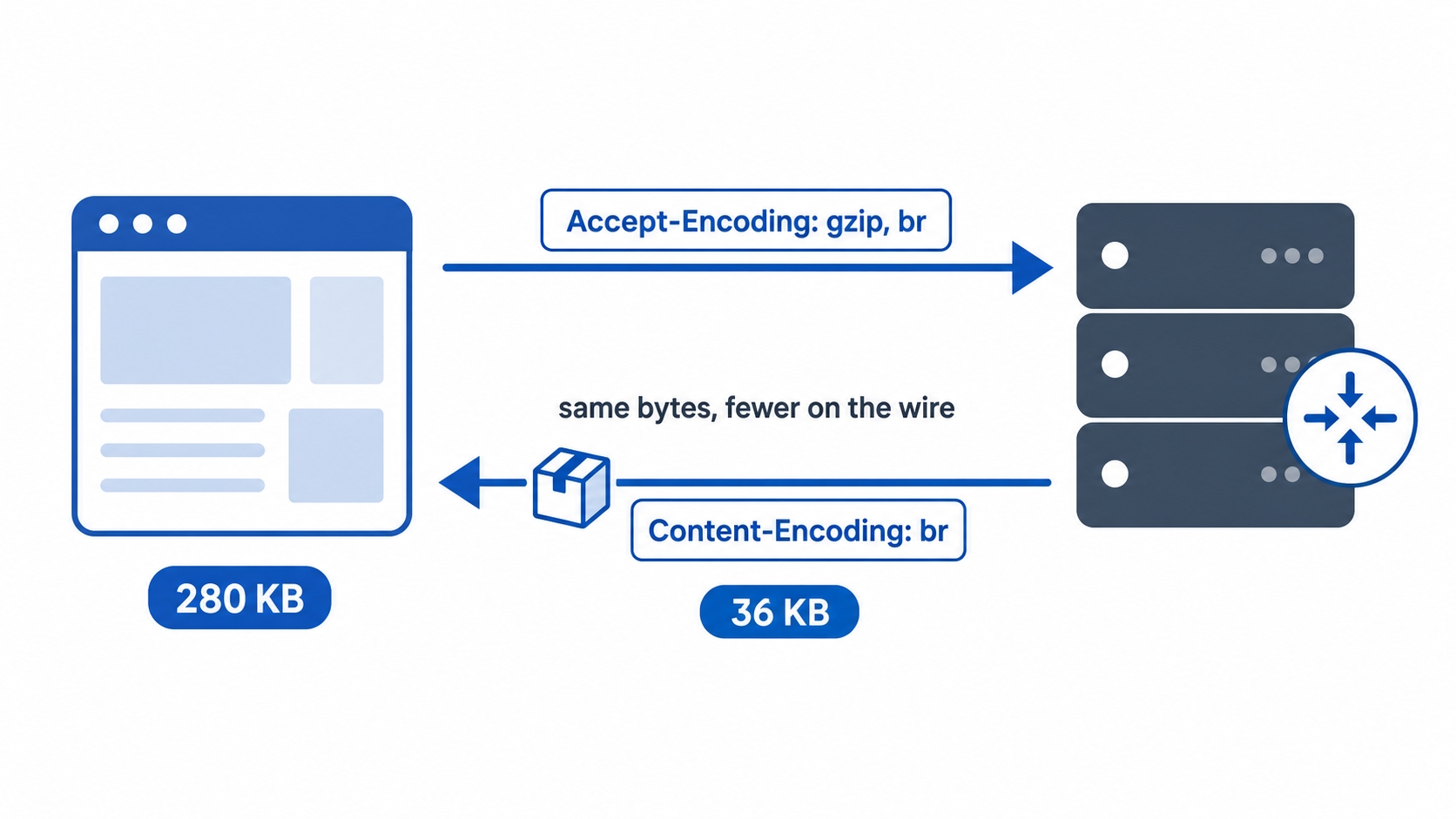
Compression is negotiated, exactly like the format negotiation from the previous chapter. The client offers what it can decode, and the server picks from that offer.
How Accept-Encoding and Content-Encoding shrink a response
It is a two-header handshake:
The client sends Accept-Encoding listing the methods it understands.
The server compresses the body with one of them and sends Content-Encoding naming the method it chose.
A real browser request carries something like this:
Accept-Encoding: gzip, deflate, br
http
That line says "I can decode gzip, deflate, or brotli; pick whichever you like." The server compresses with one of them and reports its choice on the way back:
Content-Type: text/css; charset=utf-8
Content-Encoding: br
Vary: Accept-Encoding
http
Content-Encoding: br tells the browser "I used brotli; run it back through brotli to get the original." The browser does that automatically before any JavaScript or any rendering happens, so your code always sees the full, decompressed body. The compression is invisible above the network layer.
A common confusion. The request header is Accept-Encoding (what the client accepts), and the response header is Content-Encoding (what the server actually did). They are a matched pair, like Accept and Content-Type. Mixing them up is the most common mistake when reading these in DevTools.
That Vary: Accept-Encoding line matters when a cache sits in the path. It tells the cache that the response depends on the request's Accept-Encoding, so a brotli copy and a gzip copy are different entries. Without it, a cache might hand a brotli body to a client that only asked for gzip, and the client would fail to decode it. Caches store and serve compressed responses; Vary is how they keep the variants straight.
gzip, brotli, and a word on deflate
You will meet three names in Accept-Encoding, and in practice two of them carry essentially all the traffic.
gzip is the old reliable. It has been in HTTP since the 1990s, every client and server supports it, and it is fast in both directions. If you do nothing else, turning on gzip is the single biggest, safest win you can hand your users.
brotli (sent as br) is newer, developed at Google and now supported by every major browser. At its higher settings it produces noticeably smaller files than gzip on text, often 15 to 25 percent smaller. The catch is that squeezing harder costs more CPU time, so brotli is usually configured to compress aggressively for files served many times (static assets) and more gently, or not at all, for one-off dynamic responses.
deflate is the third name you might see. It uses the same underlying algorithm as gzip with a thinner wrapper. It exists mostly for historical reasons and is rarely the best choice, partly because some old servers implemented it inconsistently. You can treat gzip and brotli as the two you actually reach for.
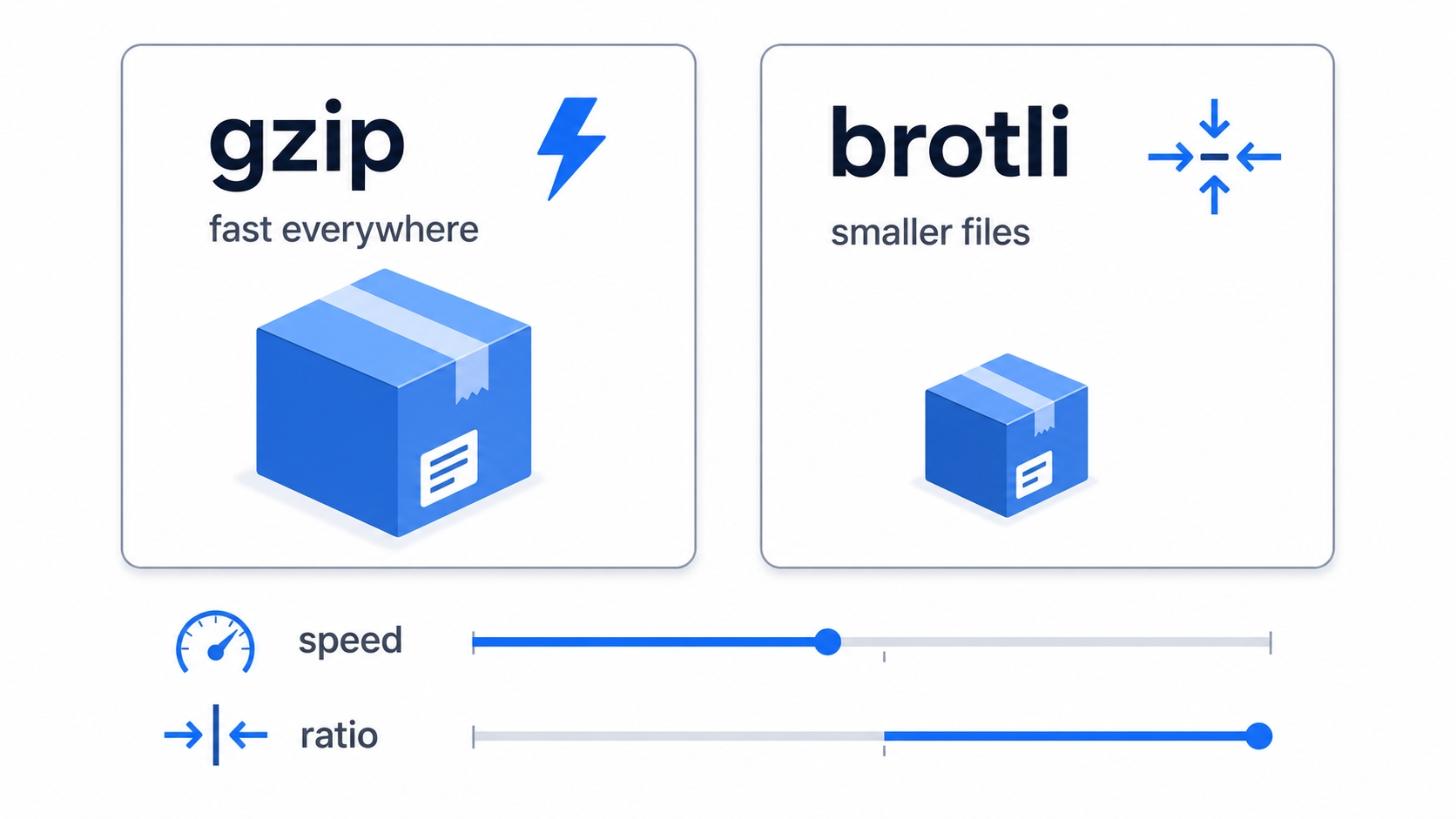
The trade-off between gzip and brotli comes down to ratio versus CPU.
gzip versus brotli trading speed against ratio
gzip
brotli (br)
Support
Everywhere, for decades
All modern browsers
Compression ratio on text
Good
Better, especially at high settings
CPU to compress
Low
Higher at top settings
CPU to decompress
Low
Low
Best fit
Anything, the safe default
Static assets compressed ahead of time
Notice that decompression is cheap for both. The client side is never the bottleneck. The cost that varies is on the server, deciding how hard to squeeze each response, which is why where and when you compress matters as much as which method you pick.
Why compressing a JPEG is wasted work
Compression only helps when there is repetition to remove, and some formats have already removed all of it. JPEG, PNG, GIF, MP4 video, MP3 audio, and .zip archives are already compressed. Their formats squeeze the data as part of saving it. By the time you have a .jpg, the easy repetition is long gone.
Run gzip over a JPEG and one of two things happens. Usually it shrinks by almost nothing, because there is no leftover repetition to find. Sometimes it grows, because gzip adds its own small header and bookkeeping while finding nothing to remove. Either way you spent CPU on both ends for no benefit, and on the rare bad case you made the file slightly bigger.
So the practical rule is simple: compress text, skip media. Stylesheets, HTML, JavaScript, JSON, SVG, and plain text compress beautifully and should always be compressed. Images, video, audio, fonts in modern compressed formats (woff2), and archives should be served as-is. Good web servers already know this and ship with a list of types to compress, but if you ever configure it by hand, that one rule covers almost every case.
For now, think of it this way. Compression is about finding patterns and storing them once. A page of text is mostly patterns, so it shrinks a lot. A photo, after JPEG has done its own work, looks like near-random bytes with no patterns left, so there is nothing for gzip to grab.
Where compression should happen
The body can be compressed at several points along the request path, and choosing well saves both CPU and latency. Recall the architecture from earlier in the course: a request often passes through a CDN, then a reverse proxy, then your application server.
Conceptually you have two questions: who compresses, and when.
On the who, you usually want compression as far toward the edge as you can push it, not buried in your application code. A reverse proxy like Nginx or a CDN is built for this and does it efficiently for every response. Your app server can compress, but it is rarely the best place. It is busy running business logic, and compressing there means every response is recompressed on the fly, even identical ones. The common pattern is to let your app emit plain, uncompressed responses and let the proxy or CDN handle encoding at the edge.
On the when, there are two modes:
On-the-fly compression happens at request time. The server compresses each response as it sends it. This is the only option for dynamic responses (a personalized dashboard, an API result), and it costs a little CPU per request. Usually you use gzip or a fast brotli setting here so the compression time does not add noticeable latency.
Static precompression happens ahead of time. During a build you compress your static files once, producing app.css.br and app.css.gz next to app.css. At request time the server just picks the matching pre-made file and sends it, paying zero compression cost per request. Because you only compress once, you can afford brotli's slowest, smallest setting. This is the standard treatment for CSS, JS, and other static assets.
The two combine cleanly in practice. Static assets get precompressed with brotli at maximum effort; dynamic responses get gzipped (or lightly brotli'd) on the fly. Either way, the client cannot tell the difference. It just reads Content-Encoding and decompresses.
Try it now
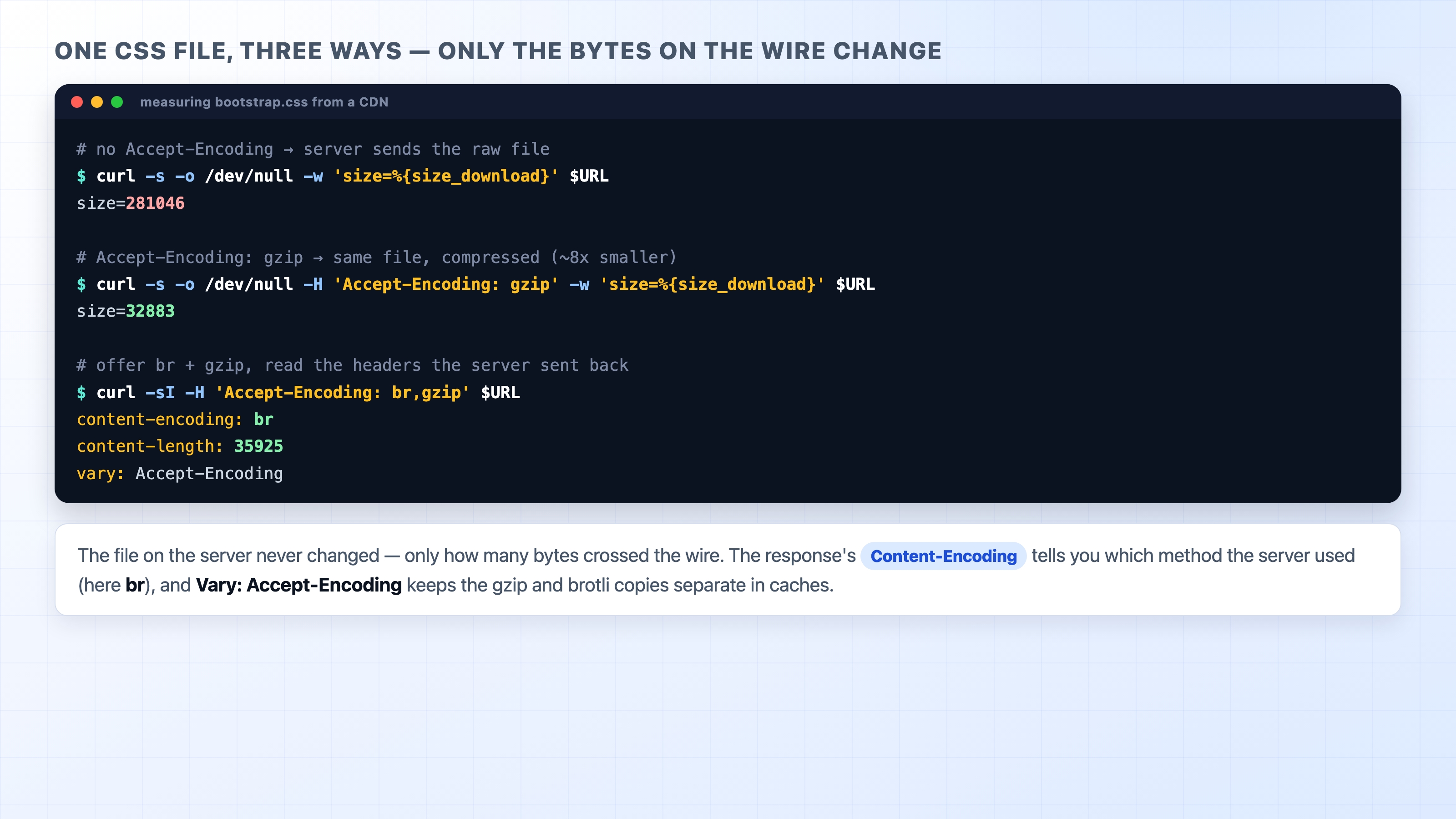
Let's measure the win on a real file. The jsDelivr CDN serves Bootstrap's stylesheet, a chunky text file, and it supports both gzip and brotli. We will ask curl for the same URL three ways and watch the transferred size change.
The -w '%{size_download}' option prints how many bytes actually came down the wire, and -o /dev/null throws the body away so we only see the number.
Measuring one CSS file with and without compression using curl
First, ask for it with no compression at all. By default curl does not send Accept-Encoding, so the server sends the raw file:
This time it reports about 32883 bytes. The file on the server did not change. We just told the server we could accept gzip, and it sent the compressed version instead, roughly an 8x reduction. Finally, ask for the response headers and let the server pick between brotli and gzip:
You will see content-encoding: br, a small content-length, and vary: Accept-Encoding. That is the whole story in three lines: the server chose brotli, the body is a fraction of the original size, and it flagged the response as varying by encoding so caches keep the variants apart. As a contrast, try the same -w 'size' trick against an image and watch the number barely move, because there is nothing left to compress.
What's Next
You can now read the headers that shrink a response and reason about where to do the shrinking. Next we look at the body from the other side: how HTTP carries JSON, raw binary, and multi-part file uploads, since underneath every Content-Type and Content-Encoding the body is ultimately just bytes.