In Chapter 10, we made our database tests reliable. A beforeEach truncate now gives every test a clean table, ensuring the suite passes no matter what ran before it. However, that exact fix is now preventing us from running a faster suite. Truncating a shared database is only safe when tests run one at a time. This first chapter of Section 7: Testing Infrastructure gives each Jest worker its own database. Now, the integration suite can finally run in parallel without workers wiping out each other's data.
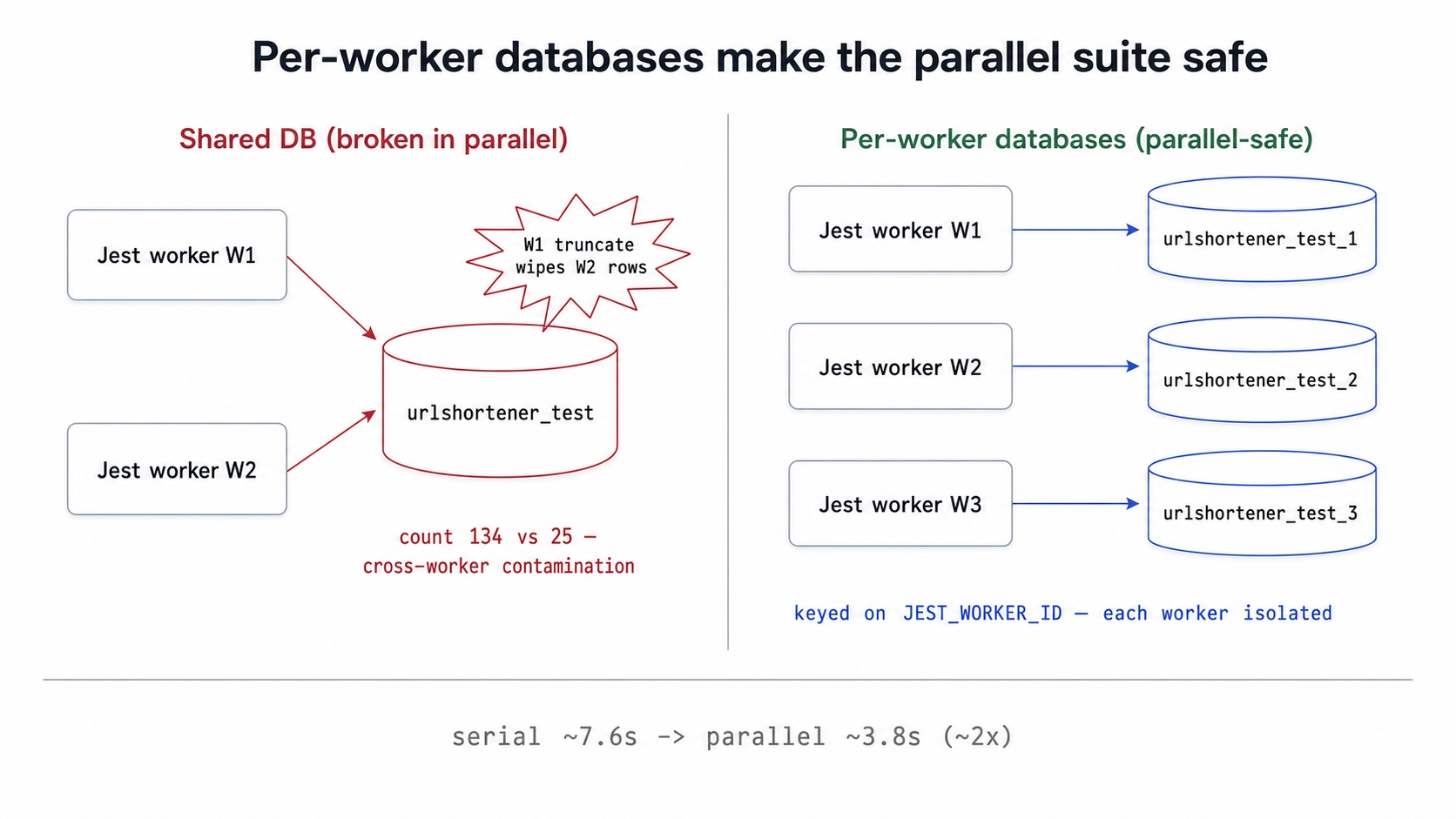
One shared test DB breaks in parallel while per-worker databases stay isolated.
Each Jest worker gets a private database named after its worker ID. This ensures parallel workers never touch the same rows.
A small script creates and migrates that database once per worker. We guard this with a catalog check because PostgreSQL does not have a CREATE DATABASE IF NOT EXISTS command.
We remove the restriction that forces tests to run serially, and we measure the speedup of running four workers at once.
What These Terms Mean
Three main ideas drive this chapter. Here is what they mean in plain English.
Jest worker. A separate Node process that Jest spawns to run test files in parallel. If you have four workers, up to four test files execute at the exact same time, each in its own process. Jest stamps every worker with an ID in the JEST_WORKER_ID environment variable. These are numbered 1, 2, 3, and so on up to your total worker count. This ID allows us to hand each worker a different database.
Parallel-Safe Jest Tests — Node.js TDD | dalabs.academy
Per-worker database. Instead of every worker sharing a single urlshortener_test database, each gets its own. They are named urlshortener_test_1, urlshortener_test_2, and so on, based on the JEST_WORKER_ID. Because the databases are physically separate, the beforeEach(truncateAllTables) function from Chapter 10 only empties that specific worker's tables. The clean-state mechanism remains exactly the same. It just runs against a private database.
Parallel safety. This means tests running at the same time cannot contaminate each other's data. A suite is parallel-safe when its results do not depend on how Jest happens to assign files to workers. Per-worker databases guarantee this safety.
Why a Shared Test DB Forces Serial Runs
Right now, we have one urlshortener_test database. Chapter 10 added a beforeEach hook that truncates every table before each test. On a single worker, this is perfectly correct. Test files run one at a time, so the truncate only clears the database for the test that is about to run.
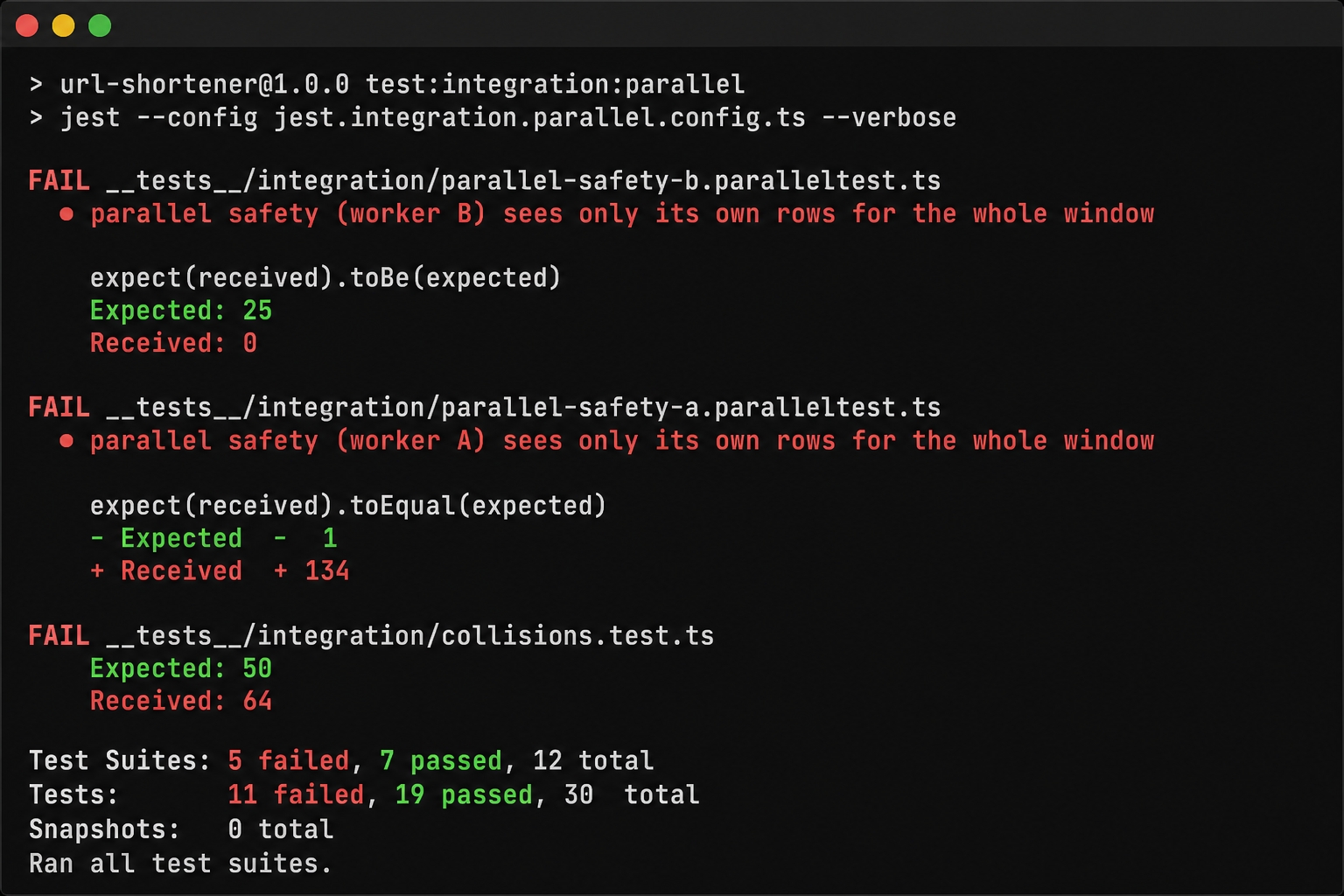
Turn on parallelism, and that same truncate becomes a bug. Worker A truncates the shared tables and starts inserting its rows. While Worker A is in the middle of a test, Worker B hits its own beforeEach hook. Worker B truncates the same shared tables and wipes out Worker A's rows. Both workers are reading and writing to one database, meaning they see each other's inserts and deletes. The assertions go haywire. A test that inserts 25 rows and expects 25 might read back 0 because a sibling worker just truncated the table. Or, it might read back 134 because three other workers are also inserting rows. A collision test expecting exactly 50 distinct inserts might count 64.
Because of this, the previous setup had only one safe option: pin maxWorkers: 1 and run the entire integration suite serially. This is correct, but slow. It also gets slower with every test we add. The fix is not to weaken the truncate from Chapter 10. The fix is to stop sharing the database. That way, each worker's truncate has nothing of anyone else's to wipe.
The Per-Worker Database Bootstrap
Each worker needs its own database, created and migrated before its first test runs. The naming is driven entirely by the JEST_WORKER_ID. Worker 3 always lands on urlshortener_test_3. The entire setup process lives in one helper file.
The CREATE DATABASE command is guarded for a specific reason. PostgreSQL does not have a CREATE DATABASE IF NOT EXISTS command. To work around this, we connect to the postgres maintenance database and ask the pg_database catalog if the worker's database already exists. We only issue the CREATE DATABASE command if the row is missing. The database name is always urlshortener_test_<id> based on the worker ID. Since it is never user input, interpolating it directly into the SQL is safe.
Creating the database gives us an empty one. The ensureWorkerDatabase function then runs prisma migrate deploy against it, pointing the DATABASE_URL at the worker's specific URL. The migrate deploy command is non-interactive. It applies the committed prisma/migrations/ exactly as written and never prompts for input. This is exactly what you want in a background worker process or in a CI environment. After it finishes, the worker owns a fully migrated database that nothing else will touch.
Why a Per-Worker Database, Not a Schema
A per-worker schema is a cheaper alternative. You can skip CREATE DATABASE entirely and just run CREATE SCHEMA worker_3 inside the shared database, which is faster to set up. We chose separate databases anyway because they provide a simpler mental model. One Postgres instance holding many databases is exactly the dev/test split from Chapter 9, just extended one level further. It also keeps the routing in one place. Our setup-env.ts file already swaps the entire connection string. Pointing a worker at a different database name requires no changes to the raw pg pool or the Prisma client. A per-worker schema would spread the routing logic across two places: the Prisma URL's ?schema= parameter and the pool's search_path. We trade a small setup cost to keep a single, obvious boundary.
Wiring the URL Per Worker
The connection strings must be rewritten before the pool or the Prisma client are ever imported. Those modules read DATABASE_URL and TEST_DATABASE_URL at import time. Jest's setupFiles array is the right place for this, since it runs synchronously before any test module loads.
This file only performs a string transformation. It does no I/O, so it stays synchronous. It rewrites both TEST_DATABASE_URL (read by the pg pool) and DATABASE_URL (read by Prisma) to the per-worker URL. This ensures both clients stay locked onto the same private database. It also stashes the original shared URL in BASE_TEST_DATABASE_URL. The bootstrap script needs that base URL to reach the postgres maintenance database. You cannot issue a CREATE DATABASE command from inside the database you are currently trying to create.
The actual create-and-migrate process is asynchronous, so it cannot live in setup-env.ts. Instead, it runs once per worker in the isolation setup file, which loads after Jest's globals exist.
The beforeEach hook is the exact same truncate from Chapter 10, completely unchanged. The new addition is the beforeAll hook. Jest's setupFilesAfterEnv re-runs for every test file, but creating and migrating the database should happen exactly once per worker, not once per file. Using a globalThis symbol solves this. A worker is a single process, and a process-level global survives across all the files that worker runs. We store the in-flight ensureWorkerDatabase promise on it using the ??= operator. The first file kicks off the create-and-migrate process, and every subsequent file in the same worker simply awaits that existing promise.
Lifting the Serial Pin
With each worker safely isolated on its own database, the integration suite can run in parallel. The change from the previous chapter is just one line.
We change maxWorkers: 1 to maxWorkers: 4. That single edit is what this entire chapter was building toward. It is only safe because the previous steps made each worker independent.
One supporting change happens in global-setup.ts. The database migration used to live there. Now that each worker migrates its own database, globalSetup becomes pure housekeeping that runs once for the entire test run. It drops any leftover urlshortener_test_* databases from previous runs using DROP DATABASE IF EXISTS ... WITH (FORCE). This prevents stale worker databases from piling up on the Postgres instance.
const result =await client.query<{ datname:string}>(
"SELECT datname FROM pg_database WHERE datname LIKE 'urlshortener_test\\_%'"
);
for(const{ datname }of result.rows){
await client.query(`DROP DATABASE IF EXISTS "${datname}" WITH (FORCE)`);
}
}finally{
await client.end();
}
};
typescript
The WITH (FORCE) clause evicts any lingering connections. This ensures the drop command does not hang waiting for a worker that failed to shut down cleanly.
What the Speedup Looks Like
On a 10-core machine, with the same per-worker machinery in place both times to ensure an apples-to-apples comparison, here is the median wall-clock time over three runs:
Mode
maxWorkers
Median wall-clock
Serial
1
~7.6 s
Parallel
4
~3.8 s
That is roughly a 2x speedup. The parallel run still pays the per-worker create-and-migrate cost, but it pays it concurrently across all workers. It wins clearly, and the performance gap will only widen as the test suite grows.
Step 1: The Flaky Parallel Run (Red)
Check out the start branch and bring the database up:
git checkout 22-test-isolation-start
npm install
docker compose up -d --wait
bash
The start branch includes a test:integration:parallel script that runs the whole suite at maxWorkers: 4. However, it does not have the per-worker database machinery yet. Every worker still shares the single urlshortener_test database. Running the parallel demo here shows the data contamination directly.
npm run test:integration:parallel
bash
Parallel workers on a shared DB see each other's rows and the suite flakes.
This failure is flaky on purpose. Over ten consecutive runs, it usually fails about half the time. When workers truly overlap on the shared database, several tests fail due to cross-worker contamination. A test expecting 25 rows might read 0 or 134, and the collision test might count 64 instead of 50. The runs that happen to pass only do so because Jest's load heuristic occasionally falls back to a single worker. That makes it accidentally serial, and therefore accidentally safe. That non-determinism is the core problem. A test suite whose results depend on how files land on workers cannot be trusted.
Step 2: Per-Worker Databases (Green)
Switch to the finish branch:
git checkout 22-test-isolation-finish
npm install
docker compose up -d --wait
bash
The finish branch adds the worker-database.ts bootstrap script. It wires the per-worker URL through setup-env.ts and setup-isolation.ts, and it flips maxWorkers to 4. The test files and the demo configuration are identical to the start branch. Only the isolation machinery has changed.
npm test
npm run test:integration
bash
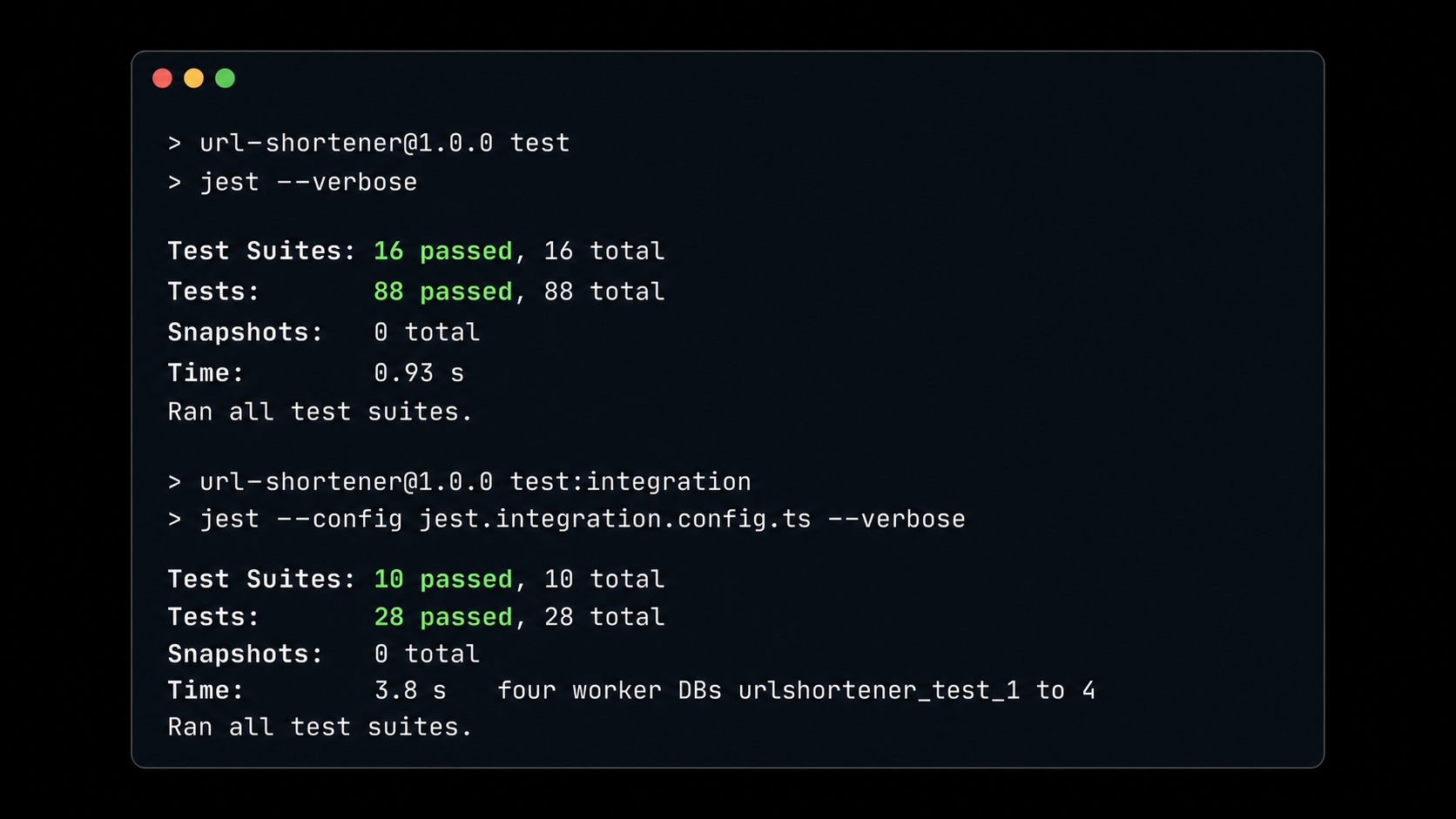
All unit and integration tests passing in parallel.
Both suites are green, and they now run in parallel. The unit suite holds at 16 suites / 88 tests, running Docker-free as always. The integration suite is 10 suites / 28 tests, running across four workers on urlshortener_test_1 through urlshortener_test_4 in about half the serial time. The exact parallel demo that flaked on the shared database is now rock-solid green across repeated runs. Because each worker owns its data, the Chapter 10 truncate can never reach past it.
What's Next
The test suite is now correct and fast on a single machine. The next chapter takes this setup to CI using a GitHub Actions pipeline. We will run Postgres as a service container so this same parallel suite can gate every merge.