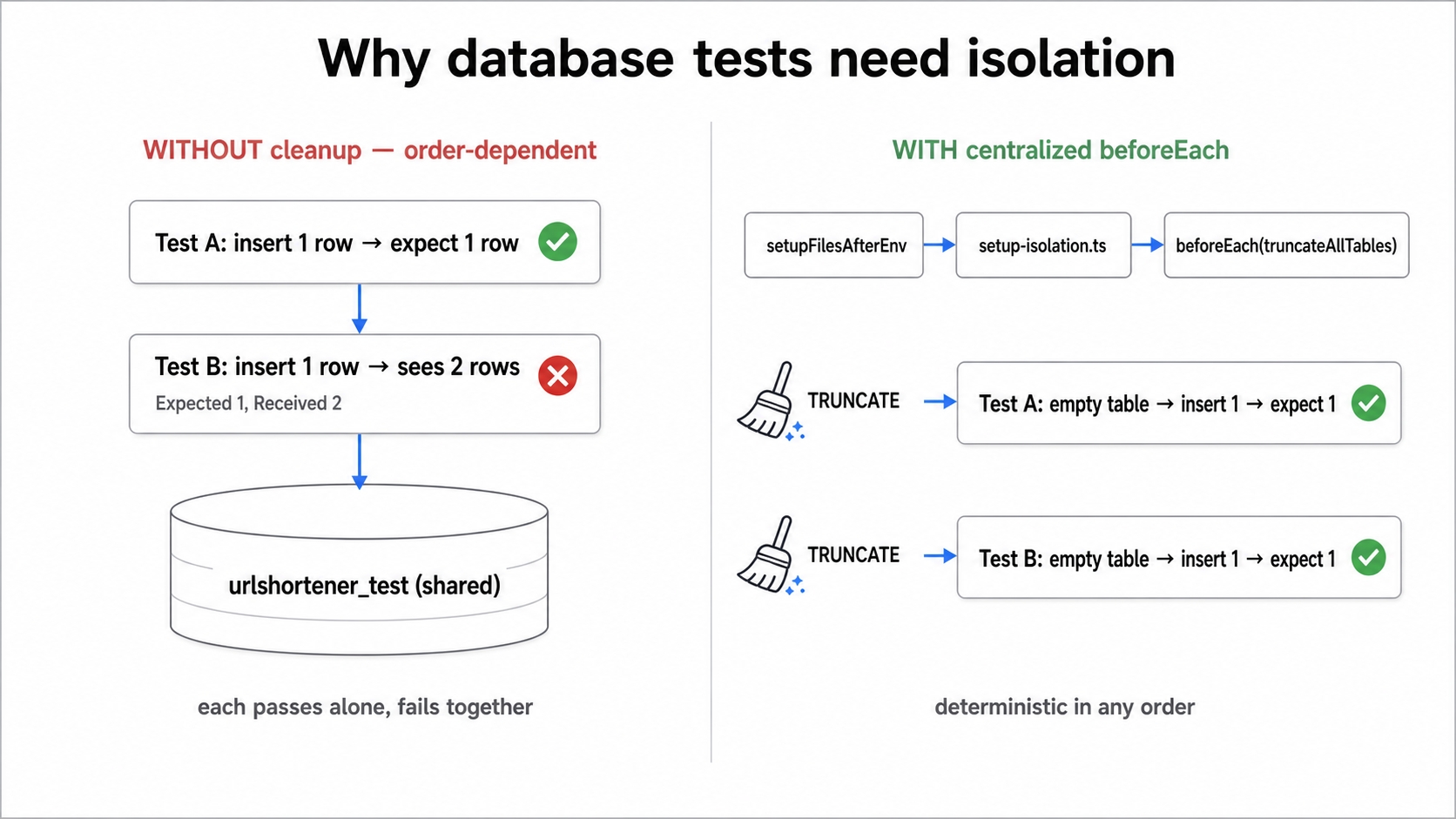
Chapter 9 gave us a real PostgreSQL database and proved our tests can reach it. But the moment tests share a real database, they also share its state. We are going to reproduce that failure honestly, then fix it so every database test starts with a clean slate.
Shared DB leakage vs a centralized beforeEach truncate.
Two integration tests that insert one row and pass alone, yet fail together. This is a live demonstration of state leaking between tests.
A centralized cleanup that wipes the database before every test, wired in through a single line of Jest config.
A look at the two standard strategies for a clean database (truncate vs. transaction-rollback) so our choice is deliberate.
What These Terms Mean
This chapter focuses on a specific failure mode and its cure. Here is the terminology you will see.
Test isolation. The guarantee that each test runs as if it were the only test, unaffected by data any other test left behind. Example: test A inserts a row, test B starts and sees an empty table.
Cross-test leakage. The opposite of isolation. State one test leaves behind pollutes the next. A real database leaks because it persists data, unlike the in-memory Map Jest hands each test file fresh.
Order-dependent / flaky test. A test that passes alone but fails alongside others, because it is polluted by state another test left behind. The classic symptom is a test that passes on your machine but fails in CI purely because the run order shifted.
Truncate. The SQL TRUNCATE statement empties a table of all its rows at once. It is faster than deleting row by row. For instance, TRUNCATE TABLE "urls_demo" wipes every row but leaves the schema in place.
One note on the table you will see below. is a throwaway teaching table created directly via SQL. It exists only to hold real, persisted rows so the leak is demonstrable. It won't collide with the real table Prisma introduces in chapter 11.
We have exactly one urlshortener_test database. Every test talks to it through the same connection pool. Rows you insert in one test are still there when the next test runs. The database persists data. That is the whole reason we use it, but it is also the reason it breaks naive tests. An in-memory Map avoids this problem because Jest hands each test file a fresh module. A shared database has no built-in reset.
Without a reset, tests become order-dependent. A test that is correct in isolation starts failing the moment another test runs first and leaves a row behind. That failure shows up as a flake: green alone, red together, and green again when the ordering shifts. A suite that flakes is worse than no suite at all. It trains you to ignore failures, and the one time a failing test means something real, you miss it.
Before we put a real Url table behind the app in chapter 11, we need to make our database tests deterministic. Every test must start from a known, clean database no matter what ran before it. We will reproduce the leak first, then fix it centrally for the whole suite.
A Throwaway Table to Make the Leak Real
We have a slight problem to solve first. The app still stores URLs in the in-memory Map from chapter 6. Prisma and the real Url table do not arrive until chapter 11. With no application table, the chapter 9 truncateAllTables helper has nothing to truncate. We cannot demonstrate cross-test pollution if nothing actually persists.
To fix this, we will create a throwaway table called urls_demo directly via SQL. It is the smallest thing that can hold real, persisted rows: an identity id and a url column.
Two details matter here. First, CREATE TABLE IF NOT EXISTS makes the setup idempotent. The suite calls it in beforeAll, and it does nothing if a previous run already created the table. Second, the name urls_demo is chosen so it never collides with chapter 11's Prisma table. Prisma's model maps to a table called Url. This one is urls_demo, a different relation with a different lifecycle, created and owned entirely by the integration suite.
Notice that countDemoUrls parses the result of COUNT(*) with Number(...). Postgres returns a count as a bigint, which the pg driver hands back as a string to avoid losing precision. If you compared it to a number without parsing, expect(...).toBe(1) would fail against "1".
Step 1: Demonstrate the Leak (Red)
Start from the red branch and install dependencies. The lockfile hasn't changed since chapter 9 because the fix uses only Jest's built-in setupFilesAfterEnv and our existing helpers. Run npm install anyway after checking out the branch:
git checkout 10-test-isolation-foundations-start
npm install
bash
The start branch ships one new test file. Both tests do the exact same thing. They insert one row, then assert the table holds exactly one row. Read on their own, each test is obviously correct.
// __tests__/integration/urls-isolation.test.ts
import{ pool }from"../../src/db/pool";
import{
createUrlsDemoTable,
insertDemoUrl,
countDemoUrls,
}from"./helpers/urls-demo";
describe("urls_demo isolation (no cleanup — leaks between tests)",()=>{
beforeAll(async()=>{
awaitcreateUrlsDemoTable();
});
afterAll(async()=>{
await pool.end();
});
it("first insert leaves exactly one row",async()=>{
awaitinsertDemoUrl("https://example.com/first");
expect(awaitcountDemoUrls()).toBe(1);
});
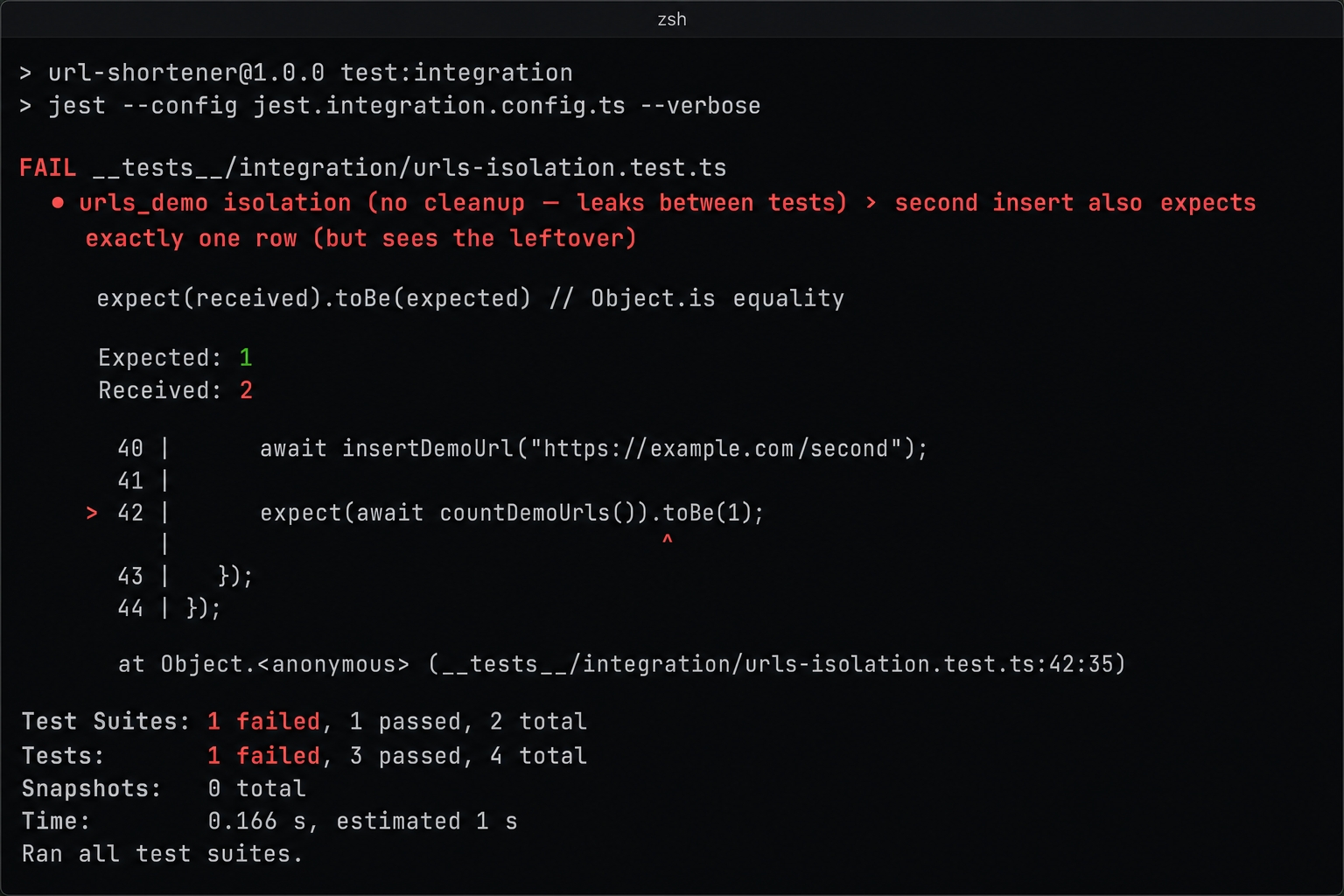
it("second insert also expects exactly one row (but sees the leftover)",async()=>{
awaitinsertDemoUrl("https://example.com/second");
expect(awaitcountDemoUrls()).toBe(1);
});
});
typescript
There is no cleanup here. Neither test removes its row, and there is no beforeEach to reset the table. The beforeAll creates the table once for the file. The afterAll only closes the pool so Jest exits cleanly. Between the two tests, nothing touches the data.
Start Postgres (the compose file lives on the chapter branch, added in chapter 9) and run the integration suite:
cp .env.example .env # first time only
docker compose up -d --wait # starts Postgres, blocks until healthy
npm run test:integration
bash
Two tests leaking state and failing together.
The suite fails with Expected: 1, Received: 2. The first test inserted its row and passed. The second test inserted its own row into the same table, which still held the first test's leftover row, and counted two. The lone failure is the second test tripping over the leftover data.
Proving it's order-dependent, not just wrong
A failing assertion alone does not prove the test is flaky. The test might just be incorrect. The way to prove order-dependence is to run the offending test by itself and watch it pass. First, reset the table so it is empty. Then run only the second test:
npm run test:integration -- urls-isolation -t "second insert"
bash
The first test is skipped and the second passes. The same assertion that failed a moment ago now goes green because no other test ran first to leave a row behind. That is the precise definition of an order-dependent suite. Each test is correct in isolation, and the failure only appears when they run together. Once we fix the isolation, both tests will pass in any order.
Two Strategies for a Clean Database
There are two standard ways to give each test a clean database. We will implement the first, but both are worth understanding.
1. Truncate every table before each test (what we implement). Before a test runs, TRUNCATE every table in the database so it starts empty.
Pros: Simple and robust. You wire one helper once. It works no matter how the code under test manages its connections or transactions. It makes no assumption that the app shares a transaction with the test. RESTART IDENTITY keeps IDs deterministic across runs, and CASCADE makes truncation order-independent across foreign keys. The database state after a run is real and inspectable, making debugging easy.
Cons: Requires a real round-trip to the database per test. This is slightly slower than a rollback, though negligible at this scale. It empties everything, so any seed or reference data has to be re-seeded if a test needs it.
2. Wrap each test in a transaction and roll back (the alternative).BEGIN before each test, ROLLBACK after. The test's writes are discarded without any explicit truncation.
Pros: Typically faster. A rollback is cheaper than physically truncating, and it never leaves residue between tests.
Cons: Invasive. The code under test has to run inside the same transaction and connection as the test. This usually means injecting that connection through the app, adding extra plumbing. It breaks down the moment the code opens its own transactions or relies on committed state. Testing commit visibility, LISTEN/NOTIFY, multiple pooled connections, or DDL all fall outside a single rollback-able transaction.
Since we are injecting a pg pool now and a Prisma client soon, truncating in beforeEach stays simpler. It matches how the app actually runs because the test and the app do not have to share a transaction. That is the strategy we will wire in.
Step 2: Centralize the Cleanup (Green)
Switch to the finish branch:
git checkout 10-test-isolation-foundations-finish
npm install
bash
The fix requires two small pieces: a setup file that registers one beforeEach, and a single line of Jest config to load it. The test file bodies do not change. Only the describe title is updated to reflect that cleanup is now centralized.
The setup file
This file imports the truncateAllTables helper we wrote in chapter 9 and registers a single global beforeEach that runs it.
Because it asks pg_tables what exists rather than naming urls_demo explicitly, it picks up the demo table automatically. It will pick up chapter 11's Url table just as automatically, with no code changes. The cleanup logic written in chapter 9 was already correct and connection-agnostic. This chapter just gives it a trigger.
Wiring it in: setupFilesAfterEnv, not setupFiles
The setup file does nothing until Jest loads it. That requires a one-line change in the integration config. Which key you use is the part that often trips people up:
There are two setup hooks in this config. They run at different times for a reason:
setupFiles runs before the test framework is installed. This is the right window for loading .env (chapter 9's setup-env.ts) because the connection strings must exist before src/db/pool.ts is imported. However, because Jest's globals do not exist yet, setupFiles cannot register a beforeEach. There is no beforeEach to call.
setupFilesAfterEnv runs after Jest installs beforeEach and afterEach into the global scope. That is exactly where a per-test hook belongs, and where our setup-isolation.ts registers its beforeEach.
A common mistake is to look for a setupFilesAfterEach key. It does not exist. The real key is setupFilesAfterEnv, meaning "after the test environment is set up," not "after each test." Register beforeEach there and it applies to every test in every integration file. This is the point of centralizing cleanup: one hook, wired once, covers the whole suite.
Why beforeEach, not afterEach
We clean before each test rather than after for robustness. If a test crashes partway through and you rely on an afterEach to clean up, that cleanup gets skipped. The crashed test's debris poisons the next test, producing a confusing cascade of failures that have nothing to do with the code being tested. Cleaning in beforeEach makes a test's correctness independent of whether the previous test cleaned up after itself. The next test wipes the slate first, unconditionally. As a bonus, the final test's data remains in the database after the run, so you can inspect what the last test left behind.
The same tests, now green
With the hook in place, the two tests pass unchanged. Run the suite:
npm run test:integration
bash
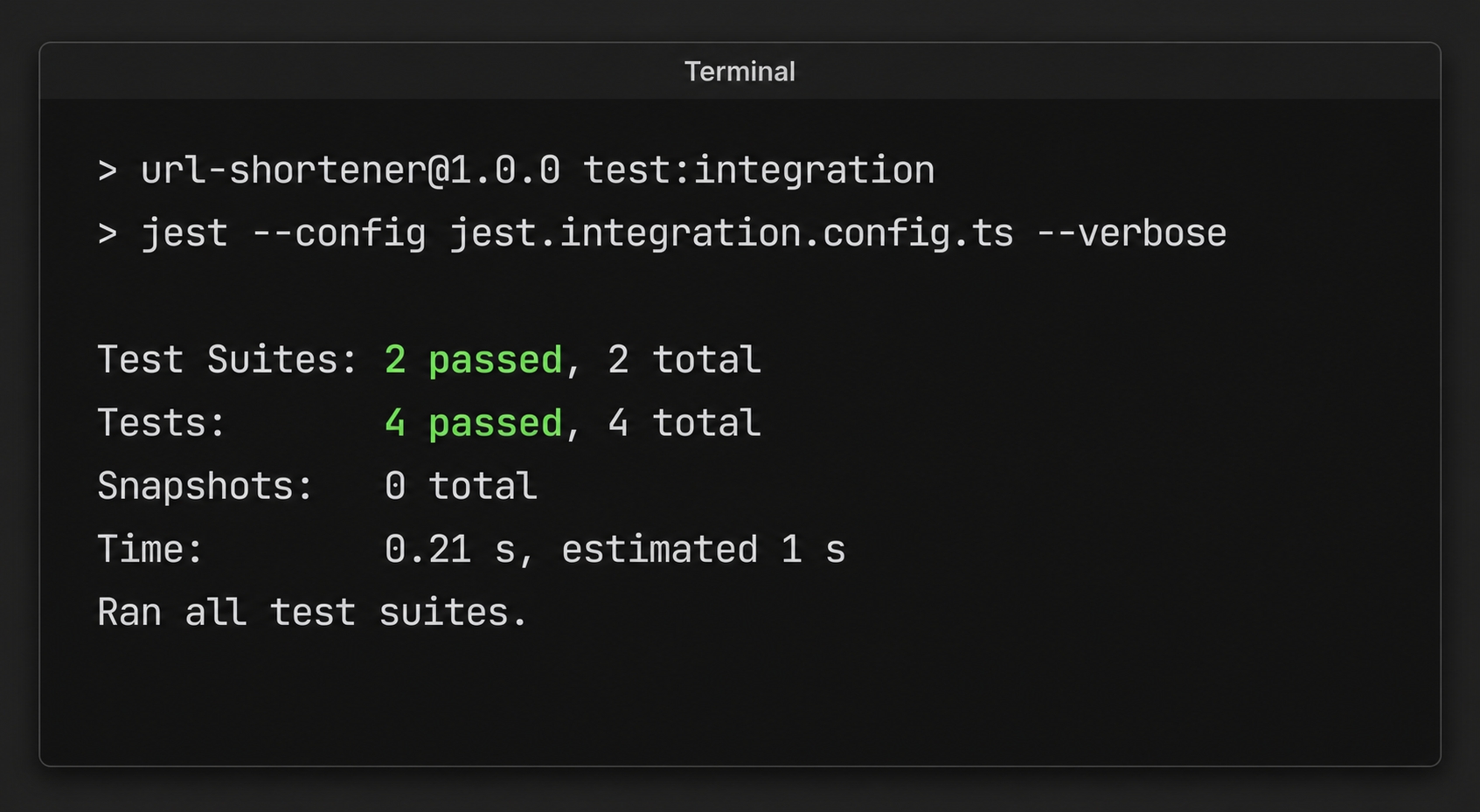
All tests passing after the change.
Both suites pass. There are four tests total: chapter 9's db.test.ts and the two isolation tests. The second test now starts from an empty urls_demo table because the beforeEach truncated it before the test ran. It inserts its one row and counts exactly one. No test body changed. The cure lives entirely in shared test infrastructure. Centralizing cleanup means tests stay focused on their own behavior and physically cannot leak state into each other.
The isolation even holds across runs. If you run the suite a second time back-to-back, the database still holds the previous run's rows. It passes 4/4 again because the beforeEach truncates that leftover data before the first test of the new run. The fast unit suite, meanwhile, is untouched and still green at six suites and thirty-two tests. Running npm run typecheck passes with no output.
What This Chapter Deliberately Leaves Out
Two concepts are intentionally out of scope for now, so you know they are coming later.
Parallel safety. Jest runs test files in parallel across multiple worker processes by default. Right now, those workers all share the one urlshortener_test database. Two workers could truncate each other's rows mid-test. This chapter establishes correctness and clean state between tests within a single worker. Making the suite correct and fast in parallel by giving each worker its own database or schema keyed on JEST_WORKER_ID is the subject of chapter 22, Advanced Test Isolation & Parallel Safety.
The demo table won't conflict with Prisma. The urls_demo table is a teaching vehicle. It is designed to coexist harmlessly with chapter 11's real table:
Different name. Prisma's model maps to Url (capitalized, Prisma's default). The demo table is urls_demo. They are different relations and never reference each other.
TRUNCATE only empties rows. The beforeEach truncate clears data. It never drops or alters the schema. Once Url coexists in the test database, truncateAllTables simply truncates both. This is exactly what you want for isolation.
CREATE TABLE IF NOT EXISTS is a no-op if the table already exists, so the demo setup never fights anything.
The scaffolding from this chapter is replaced in spirit by the real Url table next chapter, but it is harmless to leave in place. The truncate helper automatically handles whatever tables exist.
When you are done, stop the container:
docker compose down -v # stop + remove the container and delete the data volume
bash
What's Next
Every database test now starts from a clean slate, so a real table cannot make the suite flaky. Next, we will introduce Prisma and model the real Url table. We will cover the schema, the first migration, and the typed client.