Our database tests are now deterministic. Every test starts from a clean, shared urlshortener_test database. Now it is time to introduce Prisma and stand up the real Url table. The app will keep serving requests from the in-memory Map for now. We will build the schema, the migration, and the typed client here. Wiring them into the request path comes next.
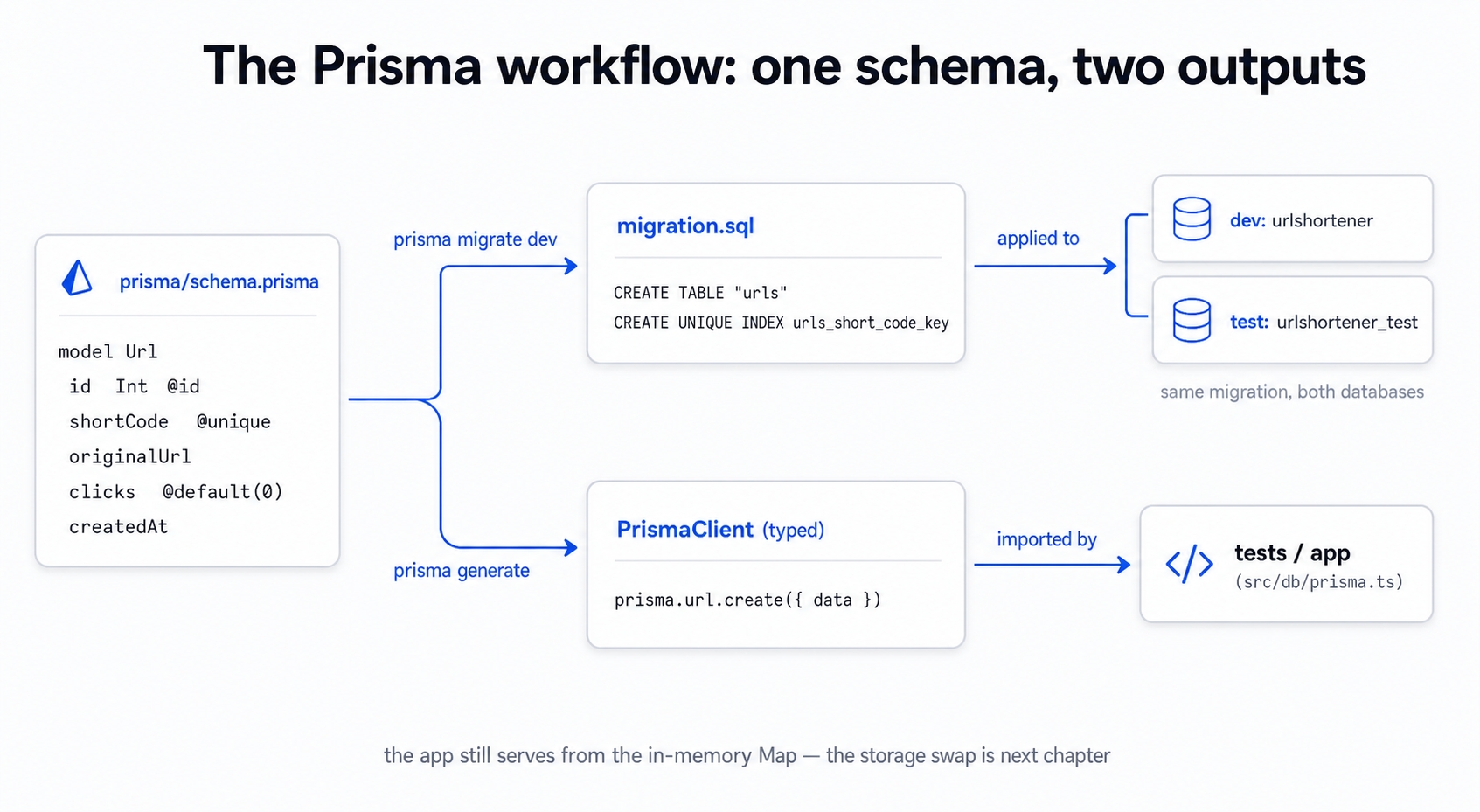
Prisma schema to migration to typed client.
A schema.prisma file describing the Url table. This is the single source of truth for both the database shape and our TypeScript types.
The first migration, generated from that schema and applied identically to the dev and test databases.
A typed client, generated from the same schema. The integration test uses this to create and read back a Url row.
What These Terms Mean
Prisma comes with its own vocabulary. Three terms carry the rest of the work, so here is what they mean in plain English.
ORM (Object-Relational Mapper). A library that lets you work with database rows as ordinary code objects instead of hand-writing SQL. For example, prisma.url.create({ data }) instead of an INSERT INTO urls ... string. Prisma is the specific ORM and migration toolkit we use.
Migration. A versioned, timestamped SQL file recording one change to the database shape, committed to git. For example, creates the table.
@unique constraint. A database-level rule that no two rows may share a value in a column. We put it on shortCode, so the database itself rejects a duplicate, not just our app code.
Why Prisma Instead of Raw SQL
So far, we have hand-written SQL through the pg driver. That works, but it leaves two gaps. First, nothing keeps the table's shape and the TypeScript types in sync. Writing pool.query<{ id: number }>(...) is just an assertion. The compiler trusts it whether or not the table actually has an id column. Second, there is no record of how the schema came to be. You run CREATE TABLE somewhere and hope every environment ran the same statements in the same order. Prisma closes both gaps from one file: schema.prisma. It declares your tables, columns, and types. The versioned migrations and a typed client are both derived from that single source, so they can never drift apart.
The tradeoffs are worth spelling out. Using an ORM is not automatically the right call:
Raw SQL (pg, what we used in chapter 9): Maximum control, zero abstraction. You hand-write every query. There is no compile-time guarantee the query shape matches the table. This is great when you need exotic SQL, but it is easy to let types drift.
Prisma: One schema is the single source of truth. It generates both the migrations and the typed client, so the database shape and the TypeScript types stay locked together. The cost is a generated client (a generate step), a query engine, and dropping to $queryRaw when you need SQL that Prisma's API cannot express.
Other ORMs (TypeORM, Sequelize, Drizzle, Knex): TypeORM and Sequelize lean on decorator and model-class patterns. Drizzle is a thinner SQL-like typed query builder. Knex is a query builder with no typed-model layer. Prisma's distinguishing feature is the schema as the source of truth, plus generated types, plus first-class migrations. That combination makes the TDD loop catch schema and code drift for us.
We pick Prisma because the typed client makes our integration assertions type-safe. The generated PrismaClient knows your schema and turns a field mismatch into a compile error. The migration workflow is also exactly what a production service and a CI pipeline need. That same workflow reappears in the database swap and the collisions chapter later in the course.
One practical note: this chapter only stands up the schema, the migration, and the typed client. The app still serves every request from the in-memory Map. The storage swap, where the routes actually start reading from Postgres, happens in the next chapter.
A word on versions. We pin Prisma to 6.19.3, the current stable release, so everyone runs the exact same setup. The commands and output will match what you see here. The specific version is not the main point. The concepts of one schema file, versioned migrations, and a generated typed client carry straight over to newer releases.
Step 1: The Failing Test (Red)
We start from a test that fails for the right reason. Check out the start branch with the Postgres container running:
git checkout 11-prisma-and-schema-start
npm install
bash
The start branch ships one new integration test: url-model.test.ts. It uses the typed Prisma client to create a Url row and read it back, asserting the persisted shape. It checks that shortCode and originalUrl round-trip, clicks defaults to 0, id and createdAt are populated by the database, and a duplicate shortCode is rejected.
// __tests__/integration/url-model.test.ts
import{ prisma }from"../../src/db/prisma";
import{ pool }from"../../src/db/pool";
describe("Url model (Prisma)",()=>{
afterAll(async()=>{
await prisma.$disconnect();
await pool.end();
});
it("creates a Url and reads back the persisted fields",async()=>{
On the start branch, none of the machinery this test needs exists yet. Prisma is not installed. There is no src/db/prisma module, no generated client, and no urls table. The test fails to even load. Bring the container up and run the integration suite:
cp .env.example .env # first time only
docker compose up -d --wait # starts Postgres, blocks until healthy
npm run test:integration
bash
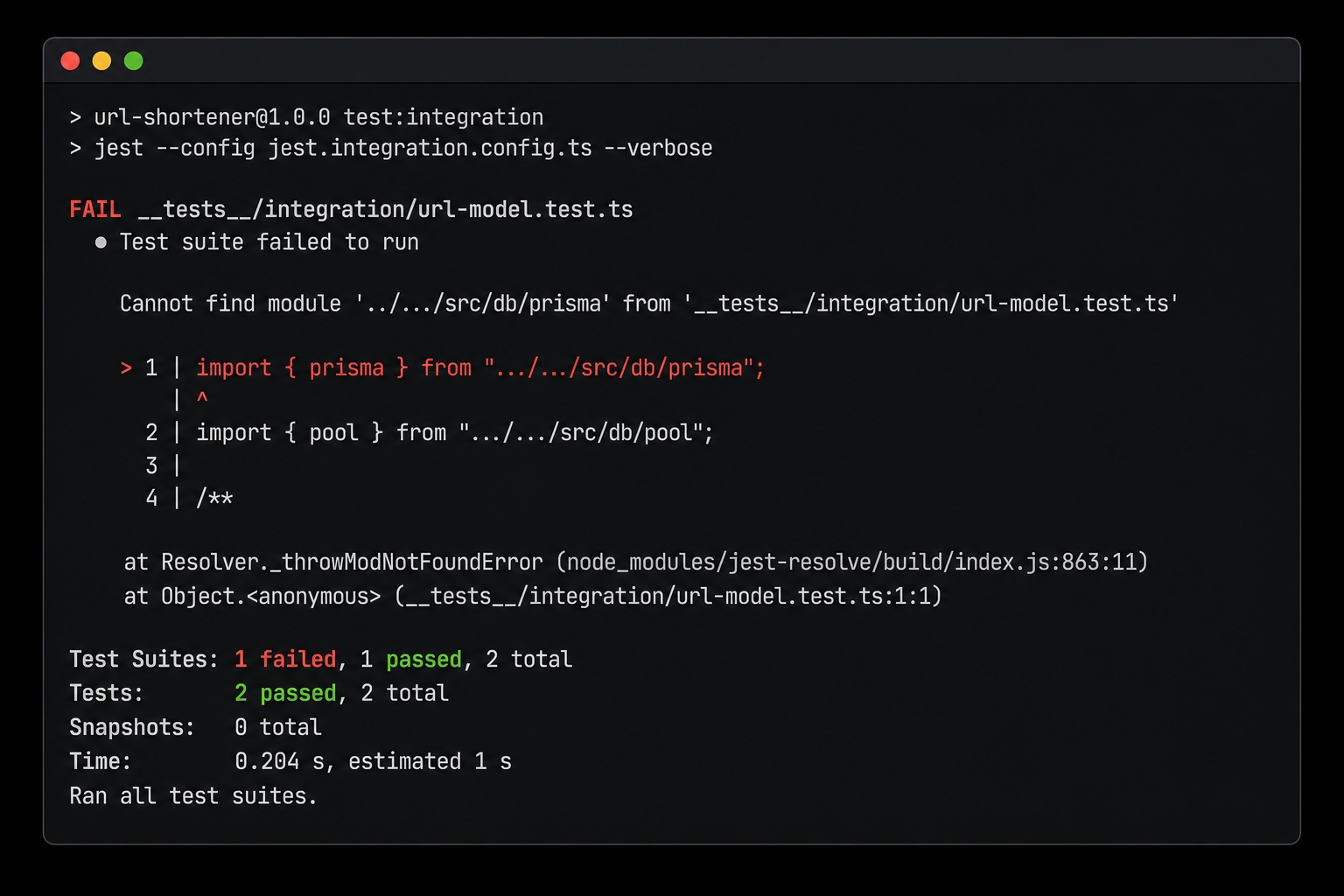
The model test failing — Prisma client missing.
The suite fails with Cannot find module '../../src/db/prisma'. The module this test imports does not exist yet. This is an honest red. The container is up, and chapter 9's db.test.ts still passes its two tests, proving the database connection itself works. The failure is the missing Prisma module, client, and table. This is exactly the gap we are about to close.
You will see the same gap from the type checker. Running npm run typecheck reports error TS2307: Cannot find module '../../src/db/prisma'. Both the test runner and the compiler agree the module is missing.
Step 2: Install and Model the Schema (Green)
Switch to the finish branch. The interesting part is what is on it, so check it out and we will walk through each piece.
git checkout 11-prisma-and-schema-finish
npm install
bash
Installing Prisma is a single pinned command. This is already in package.json on the finish branch, so npm install is enough. For reference, here is how the dependency was added:
The --save-exact flag writes 6.19.3 with no caret. A later npm install cannot quietly drift onto a different 6.x version. The package.json ends up with @prisma/client in dependencies because the app needs it at runtime. The prisma package goes in devDependencies because the CLI is a build-time tool. Finally, there is a postinstall hook.
// package.json (excerpt)
"scripts":{
"prisma:generate":"prisma generate",
"prisma:migrate":"prisma migrate dev",
"prisma:deploy":"prisma migrate deploy",
"prisma:studio":"prisma studio",
"postinstall":"prisma generate"
},
"dependencies":{
"@prisma/client":"6.19.3"
},
"devDependencies":{
"prisma":"6.19.3"
}
json
The postinstall: "prisma generate" script matters. The generated client lives in node_modules and is not committed. A fresh npm install by you, a teammate, or a CI server rebuilds it automatically. Because of this hook, you rarely need to call prisma generate by hand.
The schema
Here is the heart of the chapter: prisma/schema.prisma. It has three blocks. The generator defines how to build the client, the datasource points to the database, and the Url model defines the table.
A few decisions in that model deserve an explanation.
The datasource never hard-codes a connection string. It reads the single environment variable DATABASE_URL. This is how the same schema can target the dev database normally and the test database under Jest. We just point DATABASE_URL somewhere different. Nothing about the database credentials is committed to the repository.
The id is an internal Int @default(autoincrement()), not the public handle. It is an auto-incrementing integer (Postgres SERIAL) and is never exposed to API clients. It is small, ordered, and cheap to index. This makes the createdAt desc, id tiebreaking we will use for pagination later very inexpensive. The public identifier is shortCode. We deliberately did not reach for a cuid() or uuid() string primary key here. UUIDs are larger and non-sequential, which means worse index locality. They add nothing when the public handle is already shortCode. UUIDs make sense when IDs are exposed externally or generated client-side, which is not our case.
The @unique on shortCode is load-bearing. It creates a database-level unique index. The database itself rejects a duplicate short code, not just our application code. The collisions chapter relies on this. A retry-on-conflict strategy only works if the constraint guarantees no two rows can share a code, even under concurrent inserts. We set it up now on purpose, and the duplicate-shortCode test above already exercises it.
For naming, @@map("urls") maps the Url model to a table named urls. The @map("short_code"), @map("original_url"), and @map("created_at") attributes map each camelCase field to a snake_case column. This keeps the SQL idiomatic, since snake_case tables and columns are the Postgres convention. It also keeps the TypeScript idiomatic with camelCase fields. You get one convention on each side. You will see both halves in the migration SQL next.
The shared client
The schema.prisma file describes the database. The src/db/prisma.ts file is the runtime handle we actually import. It is tiny, and it mirrors the single-pool pattern from chapter 9.
// src/db/prisma.ts
import{ PrismaClient }from"@prisma/client";
exportconst prisma =newPrismaClient();
typescript
The PrismaClient manages its own connection pool. Exactly like the pgPool, we create one instance and export it rather than creating a new client per query. Importing it from one place gives the next chapter a single seam to swap the in-memory store for a Prisma-backed repository. For now, this client exists so we can prove the schema, migration, and typed client are real. The routes still serve from the Map.
Step 3: Run the First Migration
With the schema written, prisma migrate dev turns it into SQL and applies it to the dev database. This was run once during authoring against the urlshortener database:
npx prisma migrate dev --name init
bash
Two things happened in one command. First, Prisma wrote a timestamped migration directory, prisma/migrations/20260613091431_init/, and applied it to the dev database. Second, it ran prisma generate for us. This rebuilt the typed client so the new Url model is immediately available in code. That migration directory is committed to git. It is the durable, reviewable record of how the schema reached its current shape.
Inspect the generated SQL
Open the migration Prisma wrote. This is the entire file:
Every decision from the schema shows up here in plain SQL. It is generated DDL you can read and review:
The table is urls (@@map), and the columns are short_code, original_url, created_at (each @map). The camelCase-to-snake_case translation is exactly what we asked for.
id is SERIAL, Postgres's auto-incrementing integer, and the primary key (urls_pkey).
clicks carries DEFAULT 0, which is why the test never sets it and still reads 0 back.
created_at is TIMESTAMP(3) with DEFAULT CURRENT_TIMESTAMP, populated by the database on insert.
The @unique on shortCode becomes CREATE UNIQUE INDEX "urls_short_code_key". This is the constraint the duplicate-shortCode test trips, and the one the collisions chapter leans on.
Alongside it, Prisma writes a migration_lock.toml. This records the provider so the migration history cannot be replayed against the wrong database engine:
# prisma/migrations/migration_lock.toml
# Please do not edit this file manually
# It should be added in your version-control system (e.g., Git)
provider = "postgresql"
toml
Step 4: Migrate the Test Database, Then Go Green
The dev database is migrated, but our integration test runs against the test database, urlshortener_test. The table has to exist before the first test runs. We do not want every test author to remember to migrate it by hand. Instead, we apply the migration to the test database automatically, once, before the whole suite runs. We do this with a Jest globalSetup file.
The command is migrate deploy, not migrate dev. The deploy command is non-interactive and built for production. It applies every committed migration in prisma/migrations/ exactly as written. It never generates new ones or resets the database. That is precisely what a test database and a CI pipeline need. The migrate dev command is for authoring. It diffs the schema, creates new migrations, and may prompt the user. It has no business running unattended against a test database.
We also override DATABASE_URL to TEST_DATABASE_URL just for this command. Prisma always reads its connection string from the single DATABASE_URL environment variable. The execSync call passes a modified env object so this one migration targets the test database. The dev DATABASE_URL in .env is left untouched. We wire it into the integration config with one line:
There is a matching half to this setup. The globalSetup file migrates the test database, but the test processes also need their Prisma client pointed at the test database. Chapter 9's setup-env.ts already loaded .env. We add one block so the client inside the tests targets the test database too:
The pg pool picks dev-vs-test itself based on NODE_ENV. Prisma only knows DATABASE_URL, so we override it before the Prisma client is first imported. The result is that the migration in globalSetup and the queries inside the tests all hit the same dedicated test database. We do not have to change src/db/prisma.ts at all.
One change to truncate: keep migration history
There is a subtle interaction with chapter 10's centralized cleanup. The beforeEach(truncateAllTables) hook discovers every table in the public schema and truncates it. But the test database now has a second table we do not own: _prisma_migrations. This is Prisma's bookkeeping table that records which migrations have been applied. If truncateAllTables wiped it between tests, Prisma would think the database is un-migrated. So, the discovery query now excludes it:
const result =await pool.query<{ tablename:string}>(
`SELECT tablename
FROM pg_tables
WHERE schemaname = 'public'
AND tablename <> '_prisma_migrations'`
);
return result.rows.map((row)=> row.tablename);
};
typescript
The migration is applied once per run in globalSetup. The cleanup runs before every test. Excluding _prisma_migrations lets the cleanup empty the urls table between tests while leaving the migration history intact. The truncateAllTables function itself is unchanged. It still runs TRUNCATE ... RESTART IDENTITY CASCADE.
Retiring the chapter 10 demo table
Chapter 10 created a throwaway urls_demo table (with helpers/urls-demo.ts and urls-isolation.test.ts) purely to teach isolation, because no real table existed yet. Now that a real, migrated urls table exists, both of those files are deleted on this branch. Test isolation is now demonstrated through the real Url table. The url-model.test.ts file relies on the same centralized beforeEach(truncateAllTables) to start from an empty urls table. Keeping a parallel throwaway table alongside the real one would be confusing and redundant. The demo table did its job in chapter 10. The real table tells the isolation story from here on.
The suite goes green
Now run the integration suite against a clean test database. The globalSetup applies the migration first, and then the tests run:
npm run test:integration
bash
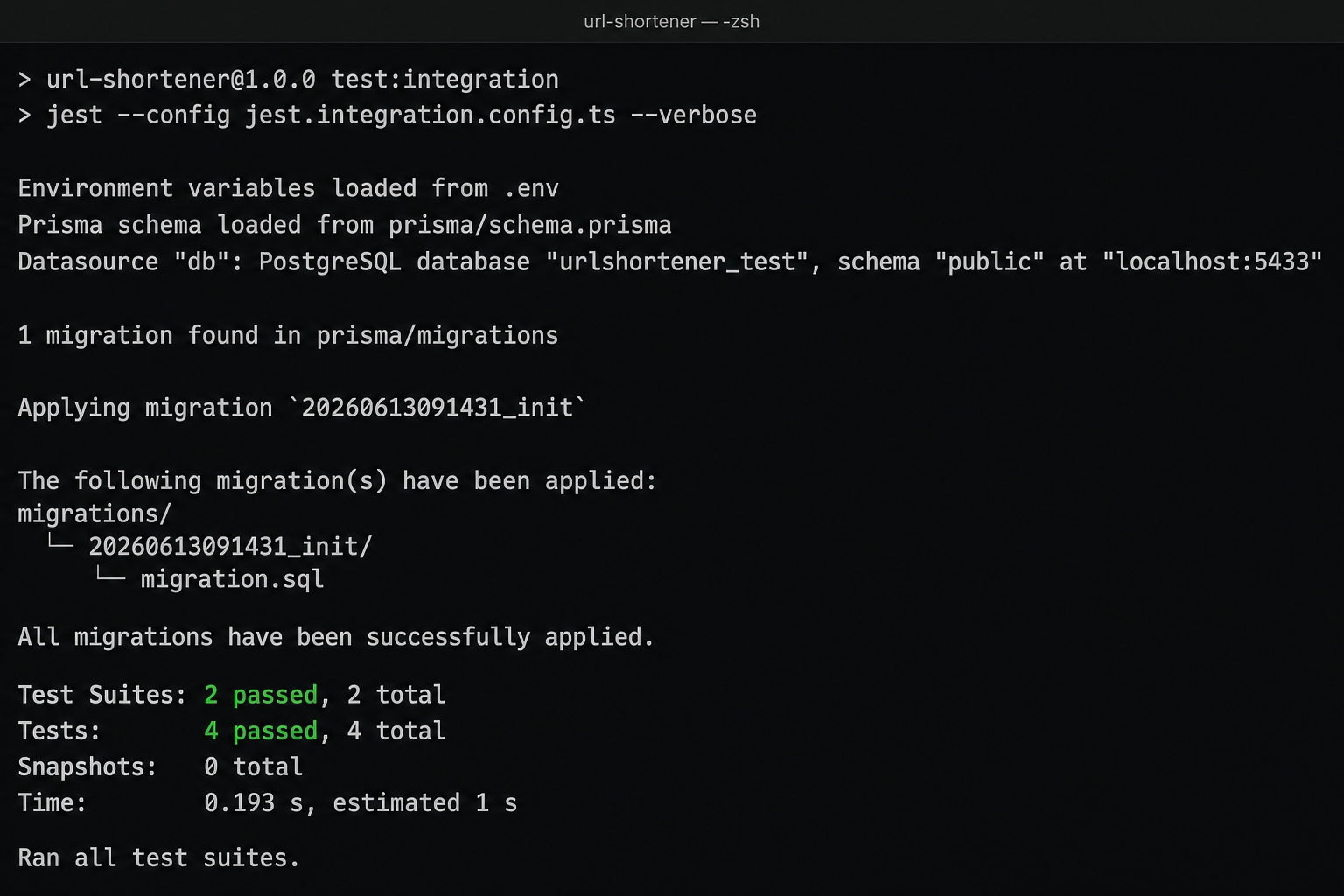
All tests passing after the change.
Green. The model test creates a Url and reads it back. The clicks field defaults to 0, createdAt is populated by the database, and the @unique constraint rejects the duplicate shortCode. The globalSetup script applied 20260613091431_init to urlshortener_test first. Then both suites passed: chapter 9's db.test.ts (two tests) plus our new url-model.test.ts (two tests), making four total.
Run it a second time and the Applying migration block is replaced by No pending migrations to apply. This is because migrate deploy is idempotent. A test database that is already migrated is left exactly as it is. The fast unit suite is untouched and still green at six suites and thirty-two tests. Running npm run typecheck now passes with no output. The src/db/prisma module the start branch was missing is real, generated, and fully typed.
When you are done, stop the container:
docker compose down -v # stop + remove the container and delete the data volume
bash
What's Next
The schema and typed client are real, but the routes still serve every request from the in-memory Map. Next, we will migrate to the database, swapping the Map for a Prisma-backed repository behind the same interface.