HTTP, Clients, Servers, and the Request/Response Model
Tung Nguyen
9 min read
Almost every step in the previous chapter's journey—and nearly every interaction in this course—follows the exact same pattern: one side asks, and the other side answers. That pattern is called HTTP (the HyperText Transfer Protocol). It is the language of the web. Once you understand this basic shape, the web feels a lot less like magic.
The whole contract: request, then response
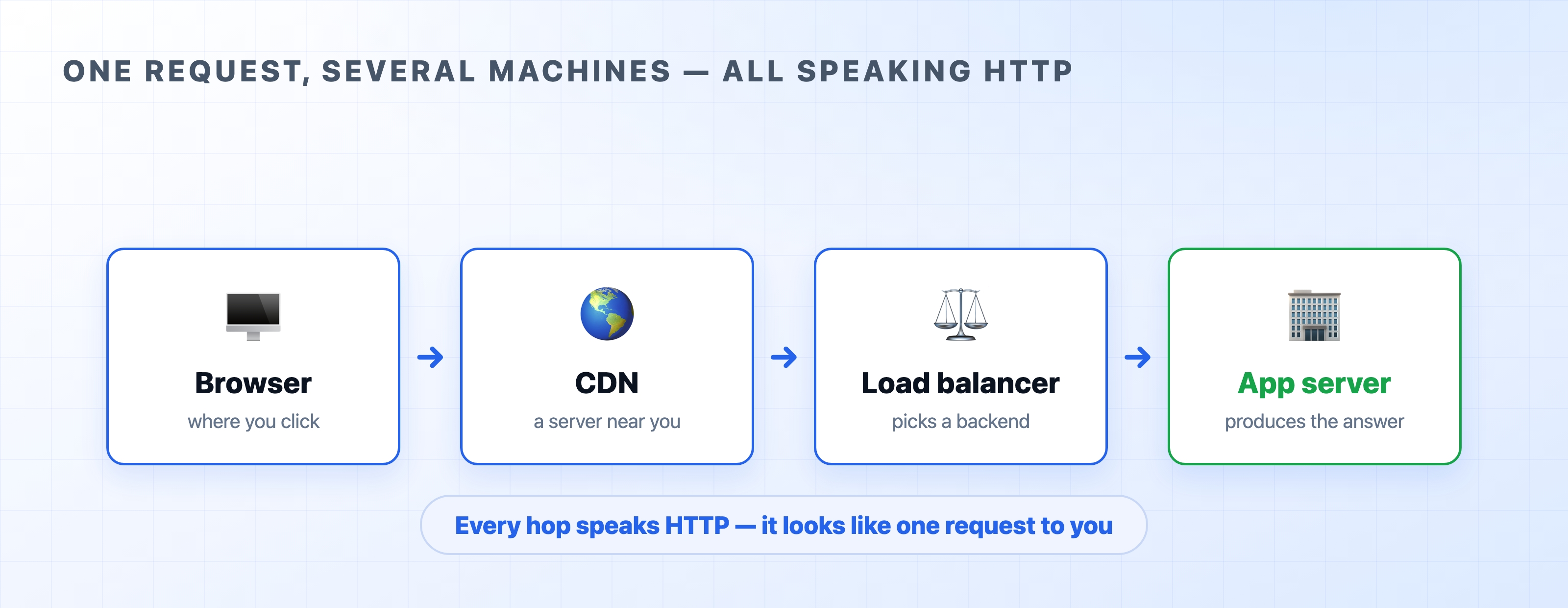
HTTP is a simple request and response protocol. One computer sends a request to explain what it wants, and the other computer sends back a response with the answer. That is the entire deal.
Two rules make this predictable. First, the client always speaks first. A server never sends anything until it has been specifically asked. Second, every request gets exactly one response. Ask a question, get an answer; the server never volunteers extra messages on its own.

Both the request and the response follow a strict agreed-upon format. This is how a browser built by Google can talk flawlessly to a server built by Microsoft. Neither side had to coordinate with the other beforehand. They just have to follow the protocol.
Client and server are roles, not machines
People usually picture the client as a laptop and the server as a massive computer locked in a data center. That picture is often true, but it misses the real definition. Client and server are simply roles in a conversation, defined by who asks and who answers. It has nothing to do with hardware.

Those big server racks are what most people picture, and they aren't wrong. But a server is literally anything that answers a request. It could be a rack in a data center, or it could be a small program running right on your laptop.