The CI pipeline now runs the full type-check, unit, and integration suite on every push. The URL shortener is fully tested and gated. This bonus chapter takes the finished service one step further and asks a scaling question. What happens to the urls table when it holds tens of millions of rows? We will migrate it to a PostgreSQL table partitioning layout. This splits one logical urls table into four physical pieces using a hand-edited raw-SQL Prisma migration. Finally, we will prove with a test that rows actually spread across the partitions while every existing endpoint stays green.
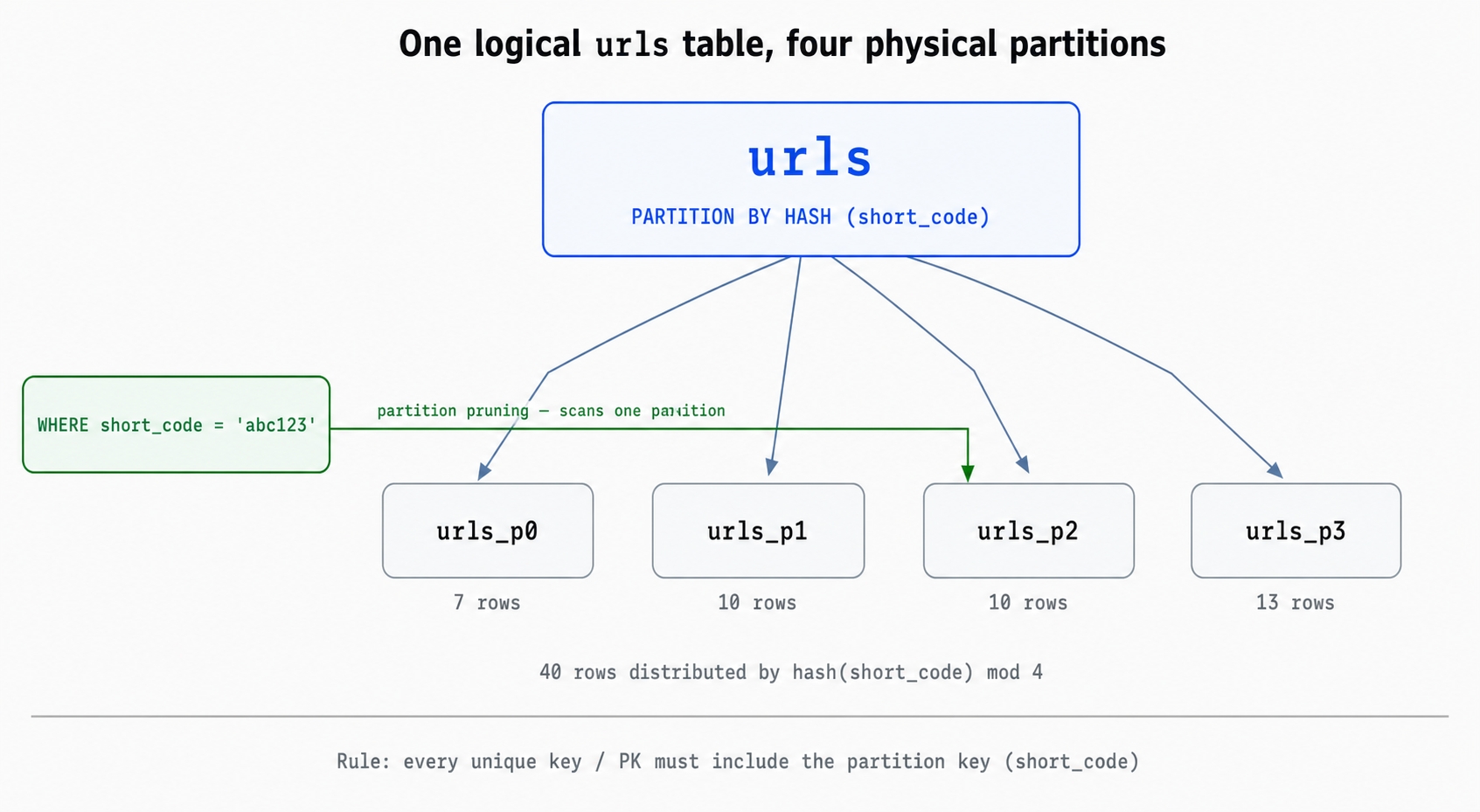
One urls table partitioned by hash into four physical pieces.
A raw-SQL Prisma migration rebuilds urls as a table partitioned BY HASH (short_code) with four child partitions, urls_p0 through urls_p3.
The Prisma model gains a composite primary key (id, shortCode). This is the only schema change needed, forced by a Postgres rule.
The repository, routes, and client API are untouched. Partitioning is a physical-storage detail the database handles for us.
What These Terms Mean
This chapter rests on three database concepts. Here is what they mean in plain English before we look at any SQL.
Table partitioning. This means splitting one logical table into several smaller physical tables, called partitions. The goal is to help the database scan far less data per query. The application still sees a single table and writes the exact same SQL. Postgres routes each row to the right partition behind the scenes. On a lookup, it reads only the partition that could hold the answer.
Hash partitioning. This is one way to decide which partition a row belongs to. Postgres hashes a column and takes the result modulo the partition count. This spreads rows evenly across all partitions. With four partitions, hash(short_code) mod 4 sends each row to one of urls_p0 through urls_p3. The alternative is range partitioning. That involves splitting by value ranges, such as one partition per month of created_at. Range partitioning suits time-series data, but it is not what we want here.
Partition key. This is the column the split is based on. In our case, it is short_code. PostgreSQL requires the partition key to be part of every unique key and primary key on a partitioned table. This constraint drives the single schema change we make in this chapter.
Two smaller terms will also come up. Postgres's built-in PARTITION BY syntax is called declarative partitioning. You declare the parent table and its partitions in SQL, and the database handles the routing without any triggers to maintain. Partition pruning is a trick the database planner uses to skip partitions that cannot match a query. For example, WHERE short_code = 'abc123' hashes the constant and reads exactly one partition instead of all four.
Why Partition at All
A single table with one big B-tree index works perfectly fine until it gets too large. As urls grows into the millions of rows, every index lookup has to walk a taller tree. Every VACUUM and reindex chews through the whole table. A sequential scan reads everything even when you only wanted a tiny sliver of data. Partitioning lets the query planner touch only the partition that could hold the row. A lookup by short_code prunes the search down to one of four pieces. This keeps the work per query roughly constant as the table grows.
There is an honest caveat here. This usually only pays off at scale. Partitioning adds planning overhead and a per-partition routing decision. It also introduces the rule that the partition key must be in every unique key, which costs us a composite primary key later on. On a table with a few thousand rows, that machinery is pure overhead. A plain table wins. The break-even point is usually somewhere in the millions of rows, or when you need to drop old data cheaply by detaching a whole partition rather than running a massive DELETE. Do not partition a small table just because you can. The constraints cost more than they save.
The choice of short_code as the partition key was not free either. Every public lookup is by short code, and a unique key on a partitioned table must include the partition key. Since short_code is already the unique column that our collision retry logic depends on, making it the partition key keeps that by-code uniqueness intact across the whole table. Range partitioning by created_at would have been better for time-series rollups. However, it would force created_at into the unique key. If we did that, two rows could share a short code on different days, breaking the collision safety we built. So, we hash on short_code.
The Partitioning Migration
Prisma cannot express partitioning in its schema language, so the migration uses raw SQL. The catch is that PostgreSQL cannot convert a plain table into a partitioned one in place. You have to build a new partitioned table beside the old data, copy the rows across, and then swap names. Here is the migration step by step.
First, set the old table aside so the new partitioned urls table can reuse its name. Renaming a table does not rename its constraints or indexes. That means urls_legacy still owns the names urls_pkey and urls_short_code_key. The new table needs those exact names. Rename them out of the way too, or the next CREATE TABLE will fail with relation "urls_pkey" already exists.
Next, create the partitioned parent. The PARTITION BY HASH ("short_code") clause makes this a partitioned table rather than a plain one. The primary key is the composite (id, short_code), not id alone. This is because the partition key must appear in every primary key.
The parent table holds no rows itself. The four child partitions hold the actual data. There is one partition for each remainder of hash(short_code) mod 4:
Next is the global unique index on short_code. On a partitioned table, a UNIQUE index can only span all partitions if it includes the partition key. Since short_code is the partition key, this is perfectly legal. It keeps short codes unique across the whole table, which is exactly what the collision retry logic relies on.
Finally, copy the existing rows across and tidy up the identity sequence. The OVERRIDING SYSTEM VALUE clause lets us write the original id values into the identity column instead of having Postgres assign fresh ones. This preserves the existing IDs. The setval function then advances the sequence past the largest copied ID so new inserts never collide with a migrated row. After that, drop the old table.
That is the entire migration. You rename the old table, rebuild the new partitioned table, copy the data, and drop the old table. The most important lines are the PARTITION BY HASH clause, the four PARTITION OF children, and the global unique index on the partition key.
The Schema Change Is One Line
The only Prisma change is the primary key. The model used to declare id Int @id @default(autoincrement()), with id as the sole primary key. Now id drops the @id attribute, and the model gains a composite @@id([id, shortCode]).
This change is forced by the partition-key rule. PostgreSQL will not let id alone be the primary key of a table partitioned on short_code. Every primary key must include the partition key. The composite (id, short_code) satisfies the rule while keeping id an auto-incrementing identity column and shortCode unique. The model's TypeScript shape does not change at all. The id, shortCode, originalUrl, clicks, and createdAt fields are the exact same types they always were.
Because the shape is unchanged, nothing downstream of the schema needs to be updated. The repository in src/services/prisma-url.repository.ts, the URL route handlers, and the database wiring are byte-for-byte identical to the previous chapter. The generated Prisma client keeps the same prisma.url.create, findUnique, update, and count API. The list() method still orders by createdAt then id, and the collision retry still catches P2002 on the short_code unique index. Partitioning is a physical-storage detail Postgres applies underneath an unchanged query surface.
This is also where the per-day click rollups teased back in the stats chapter would land. Hash partitioning is right for urls because lookups are by code. However, richer analytics like last-accessed, referrers, and per-day click counts belong in a separate append-only click_events table. That table has no by-code uniqueness requirement. It is a natural fit for range partitioning by day, where each day is its own partition. Per-day rollups would read just one partition, and thirty-day retention becomes a cheap DROP PARTITION instead of a giant DELETE. That is a deliberate future direction, though not part of this chapter.
Step 1: The Failing Test (Red)
Check out the start branch and bring the database up:
git checkout 24-table-partitioning-start
npm install
docker compose up -d --wait
bash
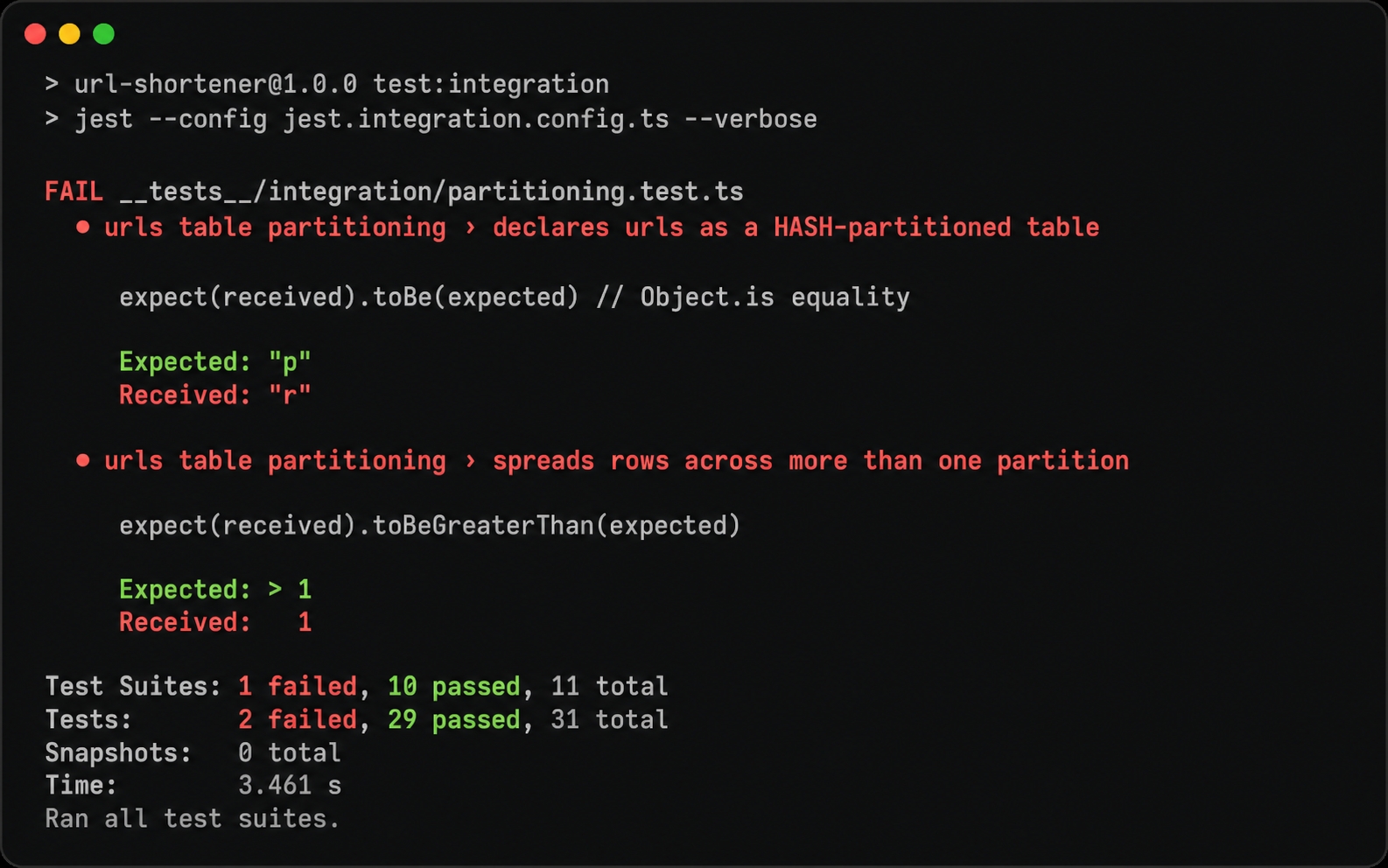
The start branch already includes __tests__/integration/partitioning.test.ts, but it does not have the migration. The urls table is still a plain table. The test queries pg_class and asserts the table's relkind is 'p' (partitioned). It then inserts 40 rows and asserts they land in more than one partition.
// __tests__/integration/partitioning.test.ts
it("declares urls as a HASH-partitioned table",async()=>{
The partitioning test fails because urls is a plain table.
Two assertions fail as expected. The relkind comes back as 'r' for a regular table, and all 40 rows land in a single table, meaning the partition count is 1. The third partitioning test checks the by-code lookup. It passes on both branches because the plain table already works functionally.
Step 2: Run the Migration (Green)
Switch to the finish branch and apply the migration:
git checkout 24-table-partitioning-finish
npm install
docker compose up -d --wait
npx prisma migrate deploy
npx prisma generate
bash
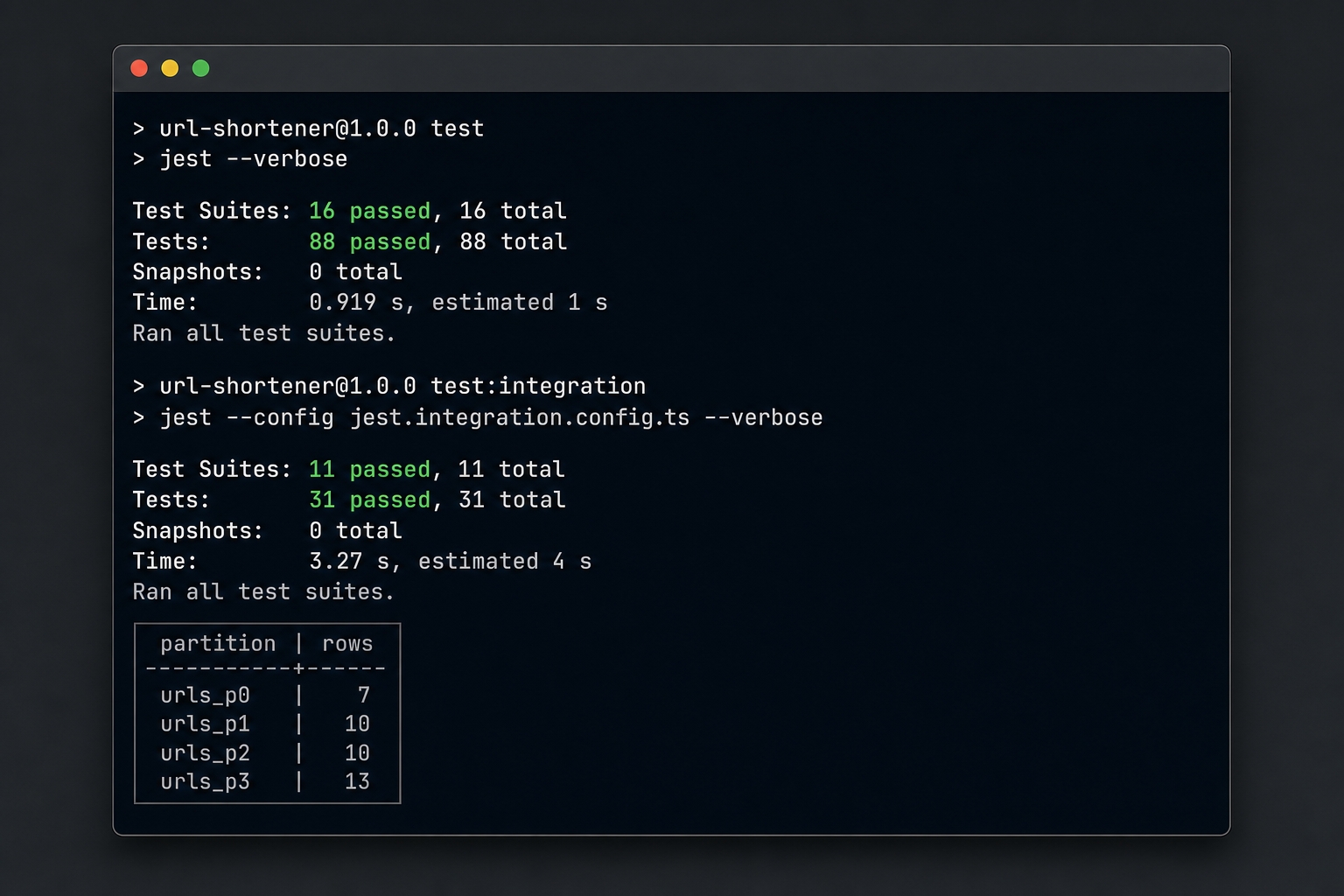
The finish branch adds the raw-SQL migration and the composite primary key schema change. Running migrate deploy rebuilds urls as the HASH-partitioned table. The relkind is now 'p', and the 40 inserted rows distribute across all four partitions. In our run, they split into 7, 10, 10, and 13 rows per partition.
All unit and integration tests passing on the partitioned table.
Both suites are now green. The unit suite holds at 16 suites and 88 tests. The integration suite is now 11 suites and 31 tests, with the partitioning proof passing against a real partitioned table. Running npm run typecheck is clean, and prisma migrate diff reports an empty migration. The schema and the partitioned database perfectly agree.
What's Next
That concludes the course. The URL shortener went from a fake in-memory store to a validated, error-mapped, concurrency-safe, CI-gated service with a partitioned database. Every single step was driven by a failing test made to pass. Take this same red-to-green discipline to your own projects. The proof you write first is the proof your code keeps working.