Our short-code generator has had a bug since chapter 7. We have gotten away with it because none of our tests run things at the exact same time. Under real traffic, two requests can try to grab the same short code at once. When that happens, one of them crashes. This is the last chapter of Section 5: Hardening & Edge Cases. We will close it out by making generation safe under concurrency and returning a sensible error if we ever genuinely run out of codes.
The collision race and its retry vs advisory-lock fixes.
Three things to keep in mind for this chapter:
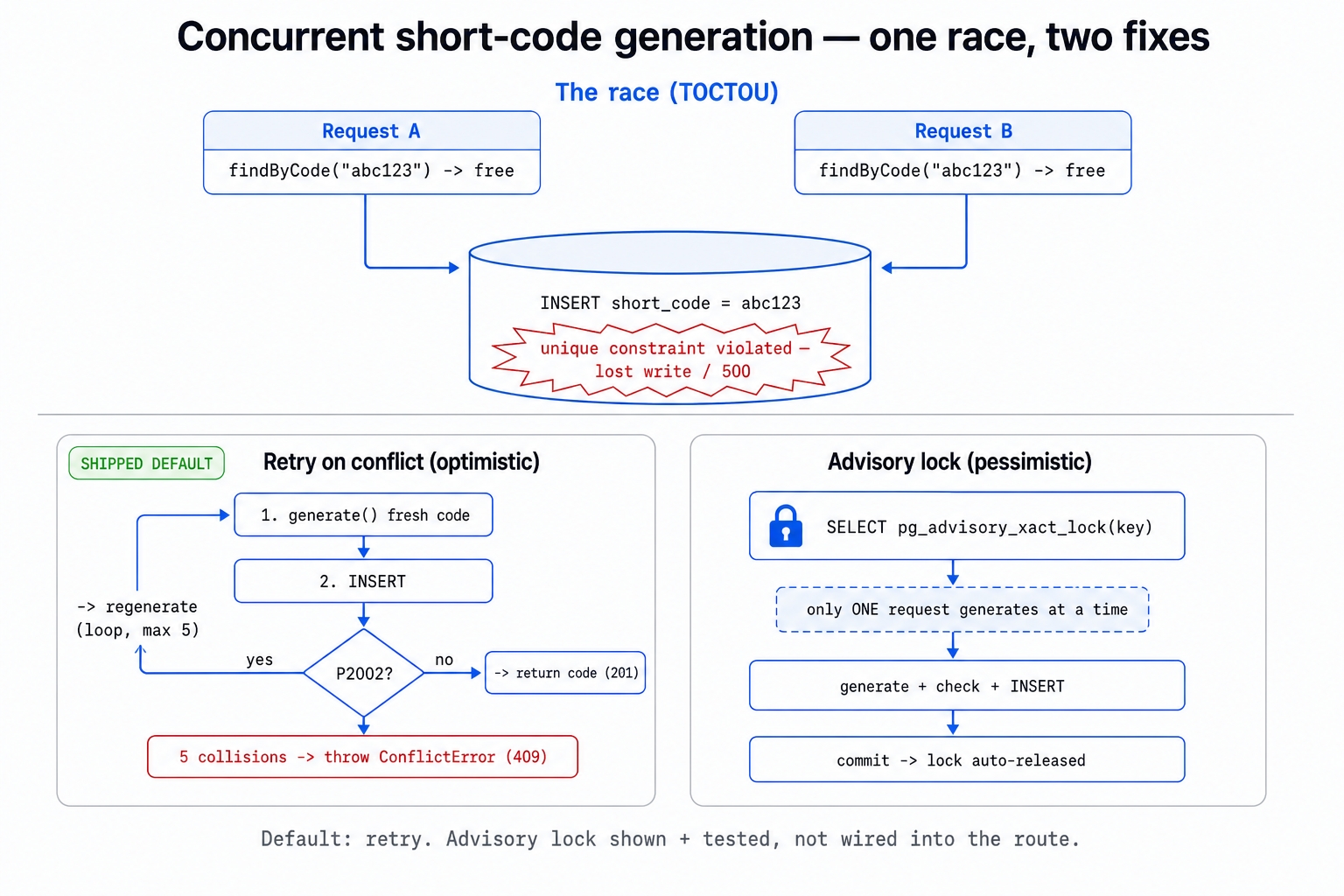
The bug. Two requests can pick the same code in the window between "is this code free?" and "okay, save it." This is a collision. It crashes the request that loses.
The fix we ship. Stop asking whether the code is free. Just try to insert it. If the database rejects it as a duplicate, draw a new code and try again. We give up with a clean error after a handful of tries.
The fix we don't ship (but show anyway). An advisory lock that only lets one request generate at a time. It works, we test it, and we deliberately leave it out of the route.
What These Terms Mean
This chapter comes down to one failure and two ways to deal with it. Before we look at any code, here is the language in plain terms.
Collision. Two different URLs happen to get assigned the same short code. Our codes are random six-character strings, so this is pure bad luck. You shorten https://a.com and the generator spits out "abc123". Later someone shortens https://b.com and the generator lands on "abc123" again. The short_code column is unique, so the database refuses the second one. With roughly 56.8 billion possible codes this almost never happens. But "almost never" still happens eventually, and a service that falls over when it does is not ready for production.
TOCTOU race. Short for Time-Of-Check To Time-Of-Use. The old code does two separate things. It checks "is this code free?" and then it inserts. Those are two steps, and under concurrency a second request can sneak in between them. Watch two requests go through it:
Request A draws "abc123" and asks "is it free?" → yes.
Request B draws "abc123" and asks "is it free?" → also yes (A hasn't saved yet).
Request A inserts "abc123". Fine.
Request B inserts "abc123" → rejected.
Both requests got told "free" because they both checked before either one had saved. The answer was true when they looked at it and stale by the time they used it. Looping will not help because the problem lives in the gap between the check and the use. That gap is exactly what the name describes.
Retry on conflict. This is the fix we will ship. Quit pre-checking. Just attempt the insert and let the unique index be the only authority on whether a code is taken. If it bounces the insert as a duplicate, catch that specific error, generate a fresh code, and go again. The insert becomes the check. The database does it as one atomic operation, so there is no gap to race through.
Advisory lock. This is the alternative. It is a lock you choose to take in PostgreSQL to force a section of code to run one request at a time. It is not tied to a row or a table. It is just a named flag the database hands to one holder until they are done. Wrap code generation in it and request B simply waits until request A finishes. They cannot pick the same code at the same instant because they are never generating at the same instant.
Optimistic vs pessimistic. Two attitudes toward concurrency. Optimistic says conflicts are rare, so let them happen and clean up afterward. That is retry on conflict. Pessimistic says conflicts are coming, so prevent them up front by locking. That is the advisory lock. We go optimistic here because collisions are so absurdly unlikely that paying a lock tax on every single write to prevent them would be a terrible deal.
The problem is a collision exposed by a TOCTOU race. The reason it matters is that it crashes a request or, in the in-memory store, silently throws a write away. The fix is retry-on-conflict, with advisory locks along for the ride as the pessimistic counterpart.
The Race We've Been Carrying
Here is the generator from chapter 7. Read it as a check, then a use, with a gap in between:
The route used it the obvious way. It generated a code that findByCode said was free, then called save. In a single-threaded test that is bulletproof. Under real concurrency it is the TOCTOU race from above. The check and the save are two separate steps, so two requests can both see "free" and both go to insert. One insert wins. The other hits the urls.short_code unique index. Prisma throws P2002 (its error code for a unique-constraint violation), nothing catches it, and the user gets an unhandled 500 error.
The in-memory store had it even worse. Its old save just overwrote on a duplicate, so request B's URL would quietly clobber request A's. That is a lost write. It is a save that looks like it worked but leaves nothing behind, and there is no error to tell you it happened.
The fix is to stop trusting the pre-check. The database already guarantees uniqueness, so let it be the source of truth and recover when it complains.
Strategy 1: Retry on Conflict (what we ship)
This is the optimistic route. Collisions are rare. Since 62⁶ is about 56.8 billion codes, we can let the rare collision happen and recover from it. Draw a code, try to insert, and if the unique index rejects it, draw another and try again. There is no pre-check and no race. The insert is the check, and the database runs it atomically.
First we need to spot a conflict. Prisma gives us a typed error with code P2002 for any unique-constraint violation:
`Could not generate a unique short code after ${maxAttempts} attempts`
);
}
typescript
A couple of details are worth pointing out. generate is a function, and we call it once per attempt. The store does not receive a code. It receives a way to draw one, so every retry gets a genuinely fresh candidate instead of the same loser again. The error handling is deliberate. A P2002 is expected and recoverable, so we continue. Anything else, like a dropped connection or some constraint we did not plan for, is not ours to swallow. We rethrow those and let the chapter-18 handler turn them into a 500.
The loop is bounded on purpose. After DEFAULT_MAX_ATTEMPTS collisions we throw the ConflictError from chapter 18 instead of spinning forever. That bound is what turns a pathological situation into a finite, documented outcome. This protects us from a saturated code space or a generator stuck producing the same value.
DEFAULT_MAX_ATTEMPTS is 5. It is defined once in url.service.ts and shared by both stores so the retry budget is identical in the unit and integration tests:
// src/services/url.service.ts
exportconstDEFAULT_MAX_ATTEMPTS=5;
typescript
The 409 Comes for Free
When we give up, we throw ConflictError and stop. We wrote that class back in chapter 18 with a 409 status and a "Conflict" label. We also registered the centralized handler that maps any AppError to its status and a { error, message } body. The route does nothing special for the failure case. The store throws, the handler catches, and the client gets a clean 409. That is the reward for defining our error vocabulary one chapter early. The conflict path was already wired the moment we used throw.
The In-Memory Store Has to Model the Constraint
Our fast unit tests run against the in-memory UrlService with no database in sight. For the retry loop to mean anything there, the Map has to act like the unique index. It has to reject a duplicate instead of overwriting it. We add a sentinel error and make save throw it:
That guard is what kills the lost-write bug. The old in-memory save did a bare records.set, so a second insert of the same code silently replaced the first. Now a duplicate throws UniqueCodeViolation, which mirrors P2002. The in-memory saveWithUniqueCode then runs the exact same retry-and-give-up loop. It just catches the sentinel instead of the Prisma error:
`Could not generate a unique short code after ${maxAttempts} attempts`
);
}
typescript
It uses the same loop, the same budget, and the same ConflictError. The only difference between the two stores is which duplicate signal they catch. It is UniqueCodeViolation in memory and P2002 against Postgres. That is why the unit suite can prove the exact behavior the integration suite later confirms against a real index.
Wiring the Route
The route drops generateUniqueShortCode completely. Now it just hands the store a generator and lets the loop run:
That is the whole change. It is one call passing () => generateShortCode(random) so the store can draw a fresh code on each attempt. The racy pre-check is gone. It does not matter whether the store is Prisma or in-memory. Both implement the same UrlStore method, so the behavior is identical. The chapter-6 seam pays off again.
Strategy 2: Advisory Locks (the pessimistic alternative)
Retry-on-conflict lets collisions happen and recovers. The pessimistic approach goes the other way and prevents them. It makes sure only one request is ever generating a code at any given moment, so two requests cannot pick the same one at once. That is exactly what the advisory lock from the overview gives us. It is a named, app-defined lock that PostgreSQL tracks but does not attach to any row or table. The first statement in the transaction grabs the lock. Everyone else lines up and waits.
GENERATION_LOCK_KEY is just a name for the lock. Any fixed 64-bit integer does the job. It is a label inside Postgres, nothing more. The only thing that matters is that every caller uses the same value so they all line up for the same lock.
pg_advisory_xact_lock is the first statement in the transaction, and it blocks until this transaction holds the lock. Only one transaction can hold it at a time, so generation is serialized. Request B sits at the lock while request A generates, checks, and inserts. By the time B gets through, A's row already exists. That makes the old findUnique pre-check safe again. The lock closes the gap.
The lock is transaction-scoped. pg_advisory_xact_lock releases on its own when the transaction commits or rolls back. There is no pg_advisory_unlock to remember, and no way to leak the lock if the request crashes. Postgres tears it down with the transaction.
It is correct, and it is real code you could ship. But look at the cost. Every shortened URL now has to wait its turn at one global lock. You have made generation a bottleneck by design.
Retry vs Advisory Lock
Retry on conflict (shipped)
Advisory lock (alternative)
Style
Optimistic — let collisions happen, recover
Pessimistic — prevent collisions by serializing
Mechanism
Unique index rejects dup (P2002) → retry fresh code
pg_advisory_xact_lock lets one request generate at a time
Concurrency
Fully parallel; only the rare loser retries
Generation serialized — a bottleneck under write load
Give-up
After N attempts → ConflictError (409)
Lock wait; no inherent give-up
Complexity
Small; no transaction needed
Needs a transaction and a lock key
Shines when
Huge code space, collisions astronomically rare
Tiny code space, or any wasted insert is unacceptable
With 62⁶ ≈ 56.8 billion codes, a collision is so unlikely that taxing every write to prevent it makes no sense. Retry-on-conflict stays fully parallel, and only the occasional unlucky request does a tiny bit of extra work. That is why the route calls saveWithUniqueCode, and why saveWithAdvisoryLock lives in the codebase as a documented option. You would only reach for it with a tiny code space or a hard rule against wasted inserts.
A Callback to Chapter 14
We have beaten this enemy before. Back in chapter 14, concurrent redirects could both read the same click count, both add one, and both write back the same number. That was a lost update. The fix there was an atomic increment ({ clicks: { increment: 1 } } → UPDATE ... SET clicks = clicks + 1) so the database did the read-and-write as one indivisible step.
This chapter is the mirror image of that. It is the same enemy of concurrency and lost writes, but a different operation. Chapter 14 made concurrent counting of an existing row safe. This one makes concurrent creation of a new unique row safe. Counting was an atomic UPDATE. Generation is an atomic insert against a unique index, with a retry when it loses. Updates there, inserts here. The service is now safe at both ends.
Step 1: The Failing Tests (Red)
Check out the start branch and bring the database up:
git checkout 19-collisions-and-locks-start
npm install
docker compose up -d --wait
bash
The start branch ships all three new test files plus naive versions of the store methods. saveWithUniqueCode generates once and inserts once, with no retry and no duplicate rejection. saveWithAdvisoryLock has no lock at all. Everything typechecks and runs. The red here is behavioral, not a compile error.
The unit tests drive the loop two ways. The store-level suite uses a simple generator that returns a fixed sequence of codes, one per call, so the test can say exactly which inserts collide:
// __tests__/collisions.test.ts
it("retries with a fresh code when the first candidate already exists",async()=>{
The route-level suite forces the collision through the real HTTP path by injecting the randomness source. The randomFor helper expands each target code into the six [0,1) fractions whose floor(f * 62) reproduces its characters. This makes generateShortCode deterministically yield the exact code we want on the next draws:
// __tests__/shorten.collision.test.ts
it("retries past a colliding code and still returns 201",async()=>{
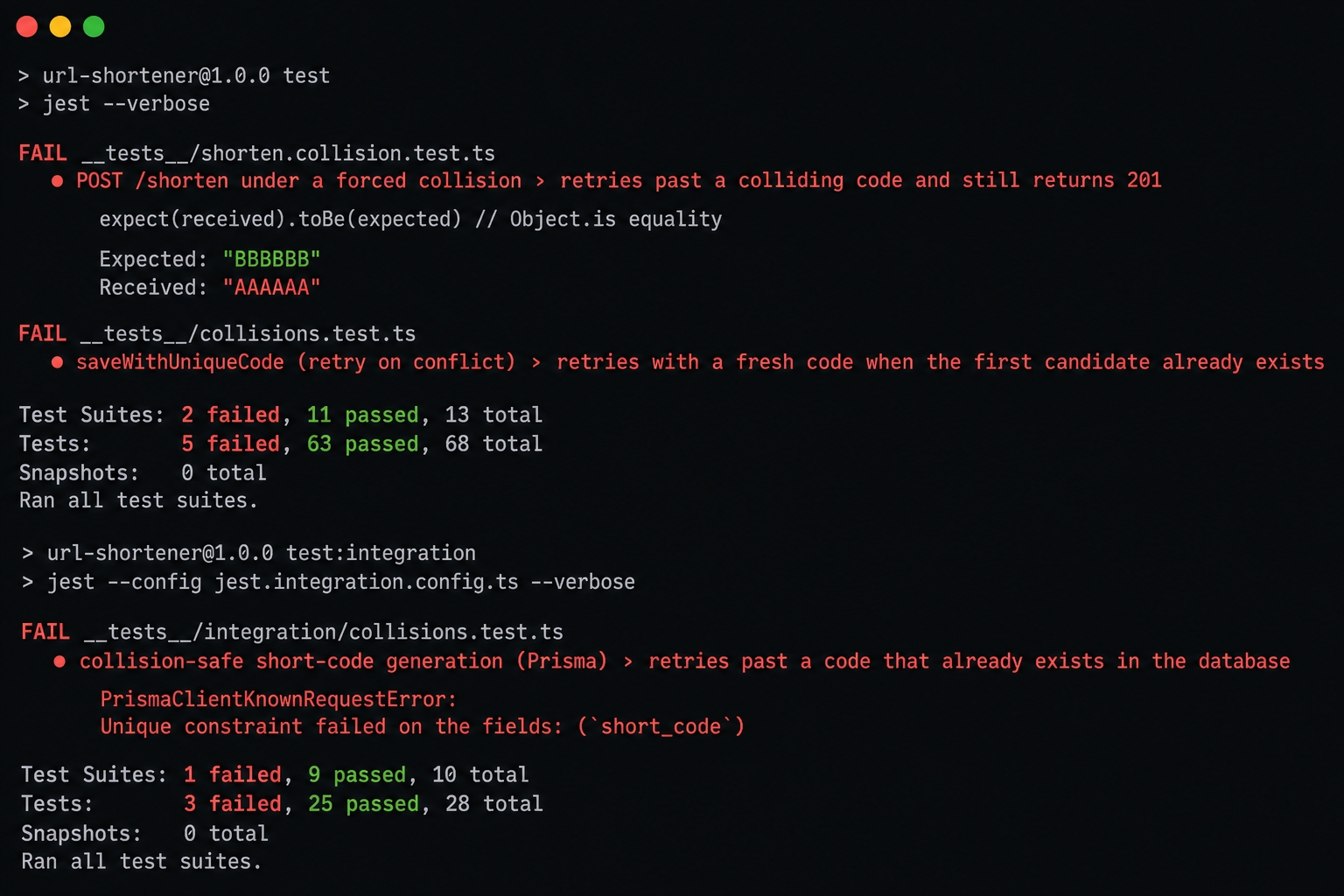
We seed the store with "AAAAAA" and set the RNG to produce "AAAAAA" then "BBBBBB". On the start branch the naive store inserts the first collision and never retries, so it returns "AAAAAA". The assertion expecting "BBBBBB" fails. A sibling test points the RNG at only the taken code so every attempt collides. It expects a 409 but the naive store happily returns 201.
The integration suite proves the same thing against a real Postgres database and shows the raw failure honestly. Run both:
npm test
npm run test:integration
bash
Concurrent inserts collide — the unique-constraint error surfaces.
Unit: 2 suites / 5 tests fail out of 13 suites / 68 tests. Integration: 1 suite / 3 tests fail out of 10 suites / 28 tests. The message is the raw PrismaClientKnownRequestError: Unique constraint failed on the fields: (short_code). That is the unhandled P2002 leaking out as a 500 error, which is precisely the production failure this chapter exists to fix. npm run typecheck passes. Again, the red is behavioral.
Step 2: Retry, Reject Duplicates, Lock (Green)
Switch to the finish branch:
git checkout 19-collisions-and-locks-finish
npm install
bash
The finish branch implements the real saveWithUniqueCode in both stores. It includes the in-memory UniqueCodeViolation so the bare save rejects duplicates. It adds isUniqueConstraintViolation and the Prisma retry loop, and it adds saveWithAdvisoryLock. The route already calls saveWithUniqueCode. It is identical on both branches because the lesson lives in the store implementation, not the wiring.
The integration suite is where the concurrency story gets proven for real. It fires 50 inserts at the live database with Promise.all so they actually race. Then it checks for no duplicates and no lost writes:
// __tests__/integration/collisions.test.ts
it("assigns a distinct code to every concurrent insert",async()=>{
new Set(results).size === 50 proves every code is distinct. prisma.url.count() === 50 proves every successful insert left exactly one row behind. There are no lost writes, which is the very failure the old silent-overwrite path would have hidden. A companion test forces a guaranteed collision. Two requests both draw "shared" first. One wins the insert, the other hits the unique constraint and retries onto its alternate. We end up with exactly two rows and "shared" present. The advisory-lock version gets the same treatment with 20 parallel saveWithAdvisoryLock calls, all codes distinct, and a count of 20.
Run both suites:
npm test
npm run test:integration
bash
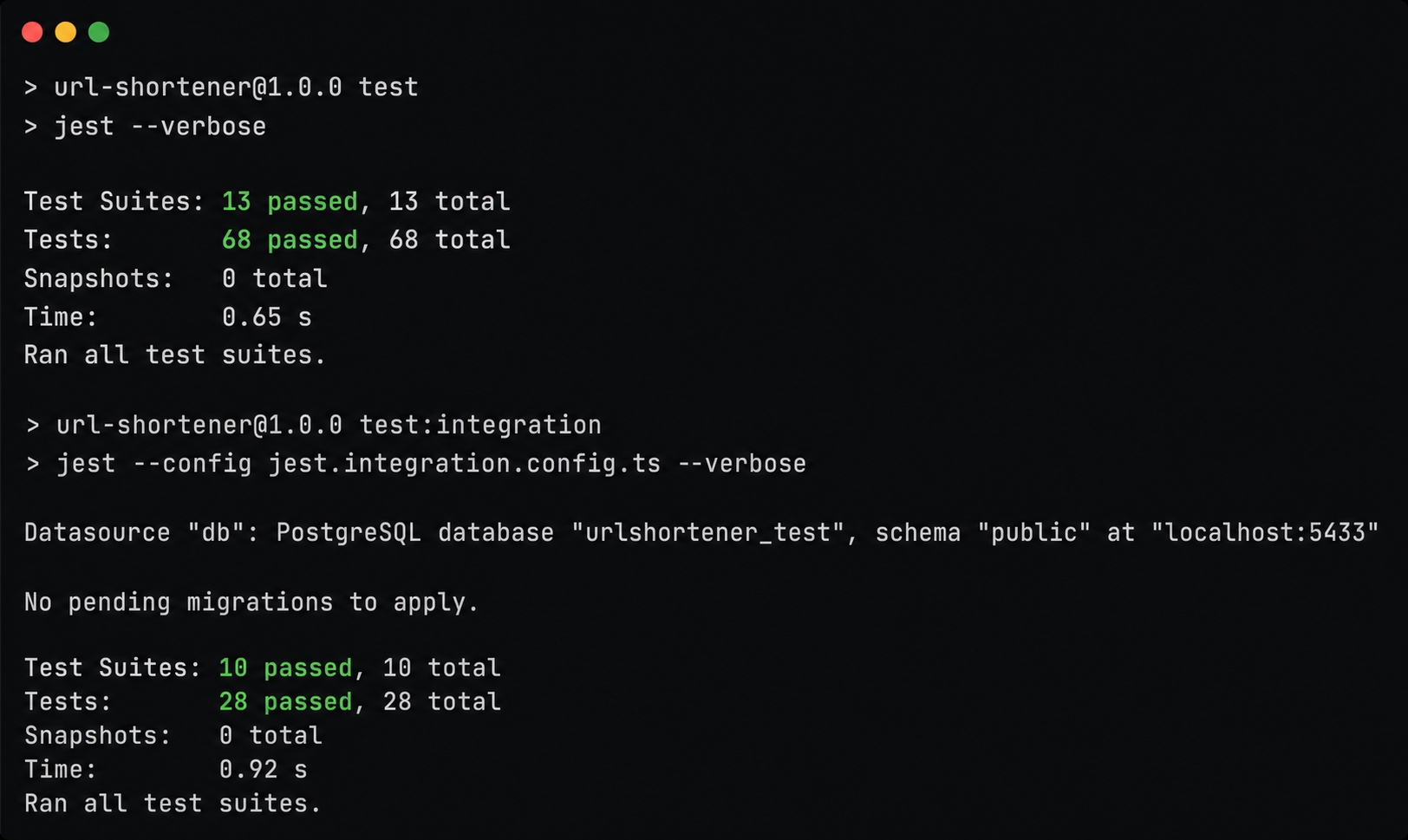
All unit and integration tests passing.
Green on both. Unit is 13 suites / 68 tests. The two new collision suites add six cases. Integration is 10 suites / 28 tests, with the concurrency proof holding steady across repeated runs. npm run typecheck passes with no output. The race is closed. The database is the single source of truth for uniqueness, the rare loser just retries, and an exhausted code space ends in a clean 409 instead of an unhandled 500.
What's Next
Section 5 is done. The service handles bad input, maps every error through one contract, and is safe under concurrent reads and writes. The next chapter kicks off Section 6: Production Readiness with Configuration & Environment Validation. We will build a single typed config module that reads process.env, validates it against a schema at boot, and fails fast with a clear message when a required variable like DATABASE_URL is missing. The point is simple: a misconfigured deploy should die at startup, not halfway through the first request.